
HAProxy 1.8 and newer allows you to use DNS service discovery to detect server changes and automatically apply them to your configuration.
HAProxy is a mature, high-performance software component that’s been reliably serving the load balancing and ADC markets for over 15 years now. Over time, the role and functionality required from HAProxy have evolved significantly. When HAProxy was first released, application architectures were quite static, and very few configuration changes occurred during runtime. Nowadays, to satisfy the requirements of modern cloud and microservices architectures, an ADC must be very flexible and it must respond to changes in its environment during runtime. Typically, this includes the requirements to:
Follow servers as they move from one IP to another
Enable dynamic scaling of backend servers
This is especially important in environments such as Amazon AWS or Kubernetes, where a scheduler is monitoring the CPU and memory usage on individual backend servers and can decide to expand or reduce the service footprint at any given point in time.
One way to update the HAProxy configuration during runtime is through HAProxy’s Runtime API. That topic was nicely covered in one of our previous blog posts – Dynamic Scaling for Microservices with the HAProxy Runtime API.
Another way to update the configuration during runtime is by using DNS for service discovery, which will be explained in this post.
Please note that the two solutions are not mutually exclusive: the DNS approach allows changing the servers’ statuses, IP addresses, ports, and weights. The Runtime API allows for even more elaborate configuration updates (agent-related configs, health checks, maxconn, ACL and MAP statements, etc.).
An important advantage of using DNS for service discovery is that there are no explicit runtime configuration changes or configuration file updates that need to take place. With the Runtime API, custom software or a script is required to invoke the Runtime API and update the runtime and/or on-disk configuration.
Service Discovery
According to Wikipedia: “[Service discovery] is the automatic detection of devices and services offered by these devices on a computer network”.
In essence, a service registry is used to monitor the network and maintain an accurate list of nodes where individual services are available. This allows other components in the network to perform efficient service discovery even when changes in configuration occur very often (such as in cloud or microservices environments).
The methods that client components use for querying service discovery systems for information can vary. Two typical ones are:
JSON/REST interface (usually restricted to a single service discovery system)
DNS – the Domain Name System
Why DNS for Service Discovery?
There are a couple of advantages to using DNS for service discovery:
DNS is a well-established standard (happy 30th birthday in November 2017!)
It makes HAProxy compatible out of the box with all service discovery systems that can expose discovery information via DNS
There is no need to implement support for a custom API to discover services
It is resilient. Don’t believe the claims that a failure in DNS may lead to a global infrastructure failure – it is up to the client components to deal with that
The disadvantages of using DNS for service discovery are:
When using A or AAAA DNS records, only the IP address of a node can be updated
When using SRV DNS records, only the IP address, network port, and server weight of a node can be updated
There may be a delay between the moment a node failure is detected and the moment the clients execute their DNS service discovery queries (while most JSON/REST implementations use long-polling mechanisms to trigger updates on the clients instantaneously)
DNS Support in HAProxy
The following section provides a summary of the DNS-related features in HAProxy.
In HAProxy 1.5, we’ve added the ability to resolve server hostnames to IP addresses using the system’s libc resolver (and the resolve.conf file). The resolution was done at startup and it couldn’t be repeated at runtime since the libc’s getaddrinfo() call is a blocking call, and it would break the even-driven nature of HAProxy.
In HAProxy 1.6, we’ve introduced a full implementation of an event-driven DNS client that was able to perform DNS resolutions and update HAProxy during runtime. The resolution that was happening during configuration parsing was still required and was done by the libc’s getaddrinfo() call mentioned above.
Only CNAME, A, and AAAA response types were supported, and the runtime resolutions were triggered by the check task (no health checks meant no runtime DNS resolution). Also, each resolution was autonomous and atomic; there was no caching and multiple DNS resolutions for the same hostname were running in parallel.
In HAProxy 1.7, we’ve enabled HAProxy to bypass the libc’s DNS resolution at configuration parsing time (see the init-addr server’s parameter).
And finally, in HAProxy 1.8 (which is expected to have a stable release in November 2017), we have introduced support for SRV query types, EDNS payload size (DNS responses up to 8K), and a dedicated timer for obsolete records. Since this version, the DNS resolution task is also autonomous and works independently of the servers’ health checks, and a DNS response cache exists (multiple objects needing to resolve the same hostname consume one query and use the same response).
DNS SRV Records
Popular service discovery systems can export data using the DNS SRV query type.
The SRV records are contained in the ANSWER section of the DNS responses and have the following structure:
| _service._proto.name. TTL class SRV priority weight port target |
Where the description of the fields is as follows:
_service: standard network service name (taken from /etc/services) or a port number
_proto: standard protocol name (“tcp” or “udp”)
name: name of the service — the name used in the query
TTL: validity period for the response (this field is ignored by HAProxy as HAProxy maintains its own expiry data which is defined in the configuration)
class: DNS class (“IN”)
SRV: DNS record type (“SRV”)
priority: priority of the target host. Lower value = higher preference (this field is ignored by HAProxy, but may become used later for indicating active / backup state)
weight: relative weight in the case of records with the same priority. Higher number = higher preference
port: port on which the service is configured
target: canonical hostname of the machine providing the service, ending in a dot
Usually, the DNS server will also return the resolution for the targets mentioned, and it will provide that information in the ADDITIONAL SECTION.
Resolution in Practice
Enable DNS service discovery by first adding a resolvers section to your HAProxy configuration. This allows HAProxy to query the given nameservers and continually check for updates to the DNS records. For example, suppose you had a DNS nameserver running at the IP address 192.168.50.30 on port 53. Your resolvers section would look like this:
| resolvers mydns | |
| nameserver dns1 192.168.50.30:53 | |
| accepted_payload_size 8192 # allow larger DNS payloads |
A resolvers section sits at the same level as the global, defaults, frontend and backend sections.
Next, add a backend that will contain your dynamically discovered servers. Use the server-template directive to create the template for the servers that will be added. It looks like this:
| backend webservers | |
| balance roundrobin | |
| server-template web 5 myservice.example.local:80 check resolvers mydns init-addr none |
The server-template directive will add the specified number of servers, which in this case is five, to the backend. Their names will be prefixed with web. Note that the resolvers parameter points to the resolvers section we added. The init-addr none parameter allows HAProxy to start up, even if it can’t resolve the hostname right away. That’s really useful for dynamic environments where the backend servers may be created after HAProxy starts.
Let’s say that your nameserver resolved the hostname myservice.example.local to three IP addresses.

DNS A records resolve a hostname to IP addresses
The DNS record might look like this:
| $ dig @192.168.50.30 -p 53 A myservice.example.local | |
| ;; QUESTION SECTION: | |
| ;myservice.example.local. IN A | |
| ;; ANSWER SECTION: | |
| myservice.example.local. 90 IN A 192.168.50.31 | |
| myservice.example.local. 90 IN A 192.168.50.32 | |
| myservice.example.local. 90 IN A 192.168.50.33 |
The server-template adds these servers to your configuration. It’s equivalent to adding a backend to HAProxy that looks like this:
| backend webservers | |
| balance roundrobin | |
| server web1 192.168.50.31:80 check | |
| server web2 192.168.50.32:80 check | |
| server web3 192.168.50.33:80 check | |
| server web4 check disabled | |
| server web5 check disabled |
Since the change is only reflected in memory, you won’t see it when inspecting the configuration file. However, you can use the HAProxy Runtime API’s show servers state servers command to see the servers that the server-template generated. First, be sure to enable the Runtime API by adding a stats socket directive to your global section:
| global | |
| log stdout local0 | |
| stats socket :9000 mode 660 level admin |
Then invoke the Runtime API to see the servers that are loaded into memory:
| $ echo "show servers state servers" | nc localhost 9000 | |
| # be_id be_name srv_id srv_name srv_addr srv_op_state srv_admin_state srv_uweight srv_iweight srv_time_since_last_change srv_check_status srv_check_result srv_check_health srv_check_state srv_agent_state bk_f_forced_id srv_f_forced_id srv_fqdn srv_port srvrecord | |
| 3 servers 1 web1 192.168.50.33 0 32 1 1 400 7 2 0 14 0 0 0 myservice.example.local 80 - | |
| 3 servers 2 web2 192.168.50.31 0 32 1 1 290 6 3 0 14 0 0 0 myservice.example.local 80 - | |
| 3 servers 3 web3 192.168.50.32 0 32 1 1 401 7 2 0 14 0 0 0 myservice.example.local 80 - | |
| 3 servers 4 web4 - 0 32 1 1 404 1 0 0 14 0 0 0 myservice.example.local 80 - | |
| 3 servers 5 web5 - 0 32 1 1 404 1 0 0 14 0 0 0 myservice.example.local 80 - |
Here you can see that five servers were added: web1, web2, web3, web4, and web5. The DNS records returned IP addresses for only three servers, though. So, the last two lines show a dash where the IP address would be.
You can also see these on the HAProxy Stats page. Enable the Stats page by adding a frontend section that looks like this:
| frontend stats | |
| bind :8404 | |
| stats enable | |
| stats uri / | |
| stats refresh 5s |
Then view the page at port 8404. In this case, I have only one server that is actually listening. So only the first server is green. The next two show as having failing health checks and are in the DOWN state. The last two, which weren’t assigned IP addresses, are in maintenance mode.
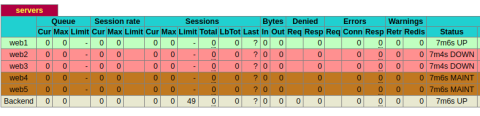
The Stats page shows each server’s status
Using DNS A records gives you each server’s IP address, but you must hardcode the port. You can also configure HAProxy to query for DNS SRV records in order to set the port in addition to the IP address. An SRV record returns a hostname and port number.
First, you’ll need to change the A records so that instead of having a hostname, myservice.example.local, resolve to multiple IP addresses, each A record will have a different hostname, such as host1, host2, and host3. Then, add the same number of SRV records and configure them to resolve a service name, such as _myservice._tcp.example.local, to the hosts you defined in your A records.

DNS SRV records resolve a service name to hosts and ports
For example, suppose your DNS server returns three A records and three SRV records, as shown:
| $ dig @192.168.50.30 -p 53 SRV _myservice._tcp.example.local | |
| ;; QUESTION SECTION: | |
| ;_myservice._tcp.example.local. IN SRV | |
| ;; ANSWER SECTION: | |
| _myservice._tcp.example.local. 0 IN SRV 0 0 8081 host2. | |
| _myservice._tcp.example.local. 0 IN SRV 0 0 8080 host1. | |
| _myservice._tcp.example.local. 0 IN SRV 0 0 8082 host3. | |
| ;; ADDITIONAL SECTION: | |
| host1. 0 IN A 192.168.50.31 | |
| host3. 0 IN A 192.168.50.33 | |
| host2. 0 IN A 192.168.50.32 |
Here, the SRV records for the _myservice._tcp.example.local service resolve to host1 at port 8080, host2 at port 8081 and host3 and port 8082. The A records resolve the IP addresses for these hosts.
Update your HAProxy configuration to look like this:
| backend webservers | |
| balance roundrobin | |
| server-template web 5 _myservice._tcp.example.local resolvers mydns check init-addr none |
Now when you invoke the show servers state servers Runtime API command, it shows both the IP address and port for each server
| echo "show servers state servers" | nc localhost 9000 | |
| # be_id be_name srv_id srv_name srv_addr srv_op_state srv_admin_state srv_uweight srv_iweight srv_time_since_last_change srv_check_status srv_check_result srv_check_health srv_check_state srv_agent_state bk_f_forced_id srv_f_forced_id srv_fqdn srv_port srvrecord | |
| 3 servers 1 web1 192.168.50.33 0 0 1 1 3 5 0 0 7 0 0 0 host3 8082 _myservice._tcp.example.local | |
| 3 servers 2 web2 192.168.50.32 0 0 1 1 1 7 2 0 6 0 0 0 host2 8081 _myservice._tcp.example.local | |
| 3 servers 3 web3 192.168.50.31 2 0 1 1 3 6 3 4 6 0 0 0 host1 8080 _myservice._tcp.example.local | |
| 3 servers 4 web4 - 0 0 1 1 2 5 2 0 6 0 0 0 - 0 _myservice._tcp.example.local | |
| 3 servers 5 web5 - 0 0 1 1 2 5 2 0 6 0 0 0 - 0 _myservice._tcp.example.local |
This is equivalent to adding a backend to HAProxy that looks like this:
| backend webservers | |
| balance roundrobin | |
| server web1 192.168.50.33:8082 check | |
| server web2 192.168.50.32:8081 check | |
| server web3 192.168.50.31:8080 check | |
| server web4 check disabled | |
| server web5 check disabled |
When you add more SRV and A records to your nameserver, they will automatically be added to the backend, filling in the web4 and web5 slots.
Conclusion
By using DNS for service discovery in HAProxy, we can conveniently scale backend servers without making explicit runtime configuration changes or configuration file updates.
If you would like to use DNS for service discovery before waiting for the stable release of HAProxy 1.8, please see our HAProxy Enterprise – Trial Version or contact HAProxy Technologies for expert advice on how to best integrate the solution into your existing infrastructure.
In parallel with continuous technical work and improvements, we are also planning on publishing further blog posts describing the effective use of HAProxy in microservices environments and integration of HAProxy with 3rd party tools and orchestration systems.
Stay tuned for more blog posts on using microservices with HAProxy, and happy scaling! Subscribe to this blog!
Subscribe to our blog. Get the latest release updates, tutorials, and deep-dives from HAProxy experts.


