In this presentation, Oren Alexandroni and Wally Barnes III bring to life their journey moving from hardware F5 load balancers to software HAProxy load balancers. Before making the switch, their hardware load balancers were costly and could not handle their traffic pattern. The new solution had to be scalable, provide low latency, be cost efficient, offer high availability and fault tolerance, and adapt to their CI/CD processes. They found that HAProxy exceeded their expectations and gave them improved observability over their services, optimized utilization of their CPU resources, and helped them to process billions of requests per day.

Transcript
Morning! Thank you all for joining us so early this morning. My name is Oren and this is Wally. We’re going to spend the next couple of minutes talking a little bit about DoubleVerify.

Just a couple of words of what is DoubleVerify, what are we doing. We were founded almost 12 years ago. We were the first to introduce a brand safety solution in the market. We’re globally across the world with about 20 offices, backed by Providence Equity, a big, private equity in the US.
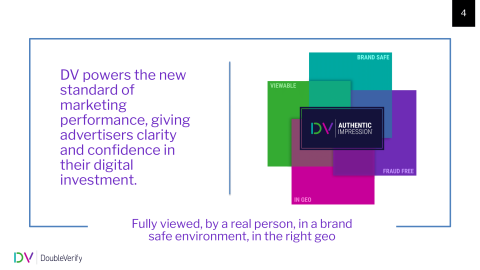
Our solution is basically a way for a publisher to know that their ad was viewed by a real person in a brand-safe environment in the right geolocation.

Some of the measurement and solutions that we can give our customers are around brand safety: make sure that their brand is safe and meets their requirements, solutions around fraud, solutions around viewability, and geolocations.

Just a couple of the brands that are using our services.

What I want to talk to you about today is our journey in load balancing. We’ve been around for a while and we’ve changed a lot of technologies and we’re going to talk about it a little bit. But we’ll start with what is online ad traffic behavior? We’re collecting a lot of data from browsers, from end users. It’s mostly HTTP and HTTPS. Today, I would say about 95% of our traffic is HTTPS. The size of the requests is very, very small; Latency? Super important. The way that we’re measuring our data is while the ad is rendering, so we’ve got to be very, very fast in order not to prevent the page from loading slowly. In terms of volume, we’re doing around half a million requests per second.

So, a little bit about our history. In 2011, when I joined the company, we had those devices. I don’t know if someone is familiar with those? Those are Cisco ACE30. They were probably top of the line, an interface card that you would put in a 6500 Catalyst switch, and it was good for 2011. Then two years later, we bought this device. That’s Critix, I don’t remember the exact model. It cost a lot; It was great for about two years.

In 2015, we bought this device. This is BIG-IP 12250v, I think, and it was great, but after a year we needed a bigger one and we got this one. I don’t know if someone ever worked with this. This is a 12U device, it’s called the F5 VIPRION. We had two data centers. In each data center we had two of those and it comes with a very nice price that you can see right here. We got a very special discount and it was only $5.2 million. At that point, we said, “All right, that’s enough. We’ve gotta find a better solution.”
So, we said, “Why are we changing?” A, it costs us a fortune. We cannot keep on doing that and building more and more data centers and spending $5,000,000 every time. It’s not scaling any more. Every time we wanted to buy more or add more, we’ve got to buy more machines and get more capacity by adding more hardware.

So, the first thing we did is to define our needs. What do we need to do? First of all and most important, scalability. We want to be able to scale very, very quickly. We want it to be cost effective. We cannot keep on paying F5 those crazy amounts of money. We wanted to be able to use commodity hardware. Buying those very expensive F5s is not a way to go any more. We want something that can handle our traffic pattern. All those devices are great in doing specific jobs; They’re not designed for online, edge traffic that is very, very quick, very small packets. Of course, we need to make sure that it’s high availability and fault tolerant. We want to be able to push changes quickly. We’re deploying changes to our production environment about ten times a day. So, we need something that can be updated very, very quickly. And, of course, it needs to be integrated into our CI\CD processes.
Right, so I’m going to hand it to Wally and he’s going to talk about how we took that and moved that to production.
Good morning! I know it’s early, we’re all sleeping off the effects of doing tech reviews of HAProxy 2.0 documents. So, you’re going to see what we use here in terms of the elements, config elements of HAProxy. They’re right along the base elements that pretty much everyone knows. While what we’ve done is notable, what we use is probably not going to seem high-tech to you.
To help keep you riveted to what’s going on up here, I’m going to do two things that you probably shouldn’t do at tech conference. The first thing I’m gonna do is I’m going to poke fun at my manager, who happens to be here on stage with me. This might result in my expense reports not being approved, I’m just saying. The second thing is I’m going to poke fun at the company that’s sponsoring this event. I don’t know what’s going to happen, they might cut my mic, there might be a new bug introduced in production called the Wally bug that somehow affects everything. We’ll see. You with me? You ready to watch me burn? Okay, alright, let’s do it.
Let’s take a quick journey back about three years. I’m interviewing with this manager at DoubleVerify, he sees on my resume “HAProxy experience” and he mentions, “Hey Wally, we’re working on an HAProxy project,” and with an ego born of two-plus decades of systems engineering and administration I say, “Yeah, I’ve used HAProxy to put some web servers behind at Bloomberg, Morgan Stanley, you know,” and I look across the table and he has this peculiar smile on his face. If you want an example, it looks like that, that was him.
So let’s fast forward to my first day and Oren says, “Hey remember that HAProxy project I mentioned? We want you to work on it, help get it established, get it rolled out and tested.”
“No problem! What web application are we gonna put behind it?”
“Well, we’re going to replace F5, so all them; but don’t worry, we’re going to start with just our main application. It’s about a couple hundred million requests a day, but in about a year we’re looking at it going to about a billion.”
“So you’re going to use HAProxy, the software load balancer, to replace F5, the dedicated device? Okay! We’re on it!”

Right? So our journey begins. This saying is something pulled from an American movie. If you’re an American, you know this ridiculous saying. It’s on every commercial. If you don’t, it’s from Field of Dreams. If you’re in IT, it’s incomplete. If you build it they will come is what they say, but if your in IT you know there’s a second part to this, is that they’re going to add more to it than they ever told you about. We had to plan not only for billions, but to be able to expand past that if necessary.

So, why HAProxy? Open-source software. We’ve all dealt with black box solutions; they’re great when they work, not so great when something’s not going right. The insight into them is often not very good. You’re dealing with tech support and hoping that they have insight, meanwhile things are burning. Open-source software is not only great because you can look at the code, but often you can use it with other open-source solutions to get what you need. So this is very important.
Having a file-based configuration means we can treat it like code, we can manage it centrally, it can be reviewed, it’s rather straightforward. Because we’re going to be adding live, disparate applications, these applications were not built together, this dev team did not build along with this dev team, so they don’t do anything alike. If we’re going to put them behind the same systems we need to be able to configure what we need for each one of these applications, and being able to configure at multiple levels—frontends, backends, the defaults, everything, listen sections—all these things come into play for us.
Having access to metrics is also important. Once again, black box solutions, if you want these kinds of insight, if you can even get them, you wind up paying for some third-party product that’s very expensive and may not even give you what you need. The flexibility we get from encryption comes because we use OpenSSL. What’s in it, we get. OpenSSL is generally, pretty robust, so that gives us a lot of options, and we need to be able to grow not only vertically, adding processes and memory, but also out in terms of boxes.

Let’s talk about the components. We use commodity hardware servers. Currently it’s Cisco, but we can use anything. We use CentOS 7, which gives us access to things like firewalld; This is important, security at all levels, even on the box. We get this simply by using CentOS. We do use rsyslog and systemd as well. We are currently using HAProxy Enterprise version 1.8 or HAPEE. We will be moving to 2.0 soon for our production or pretty much all of our pools.
To tie this up we use Ansible and Git; This is, of course, config management and code management, these two tied together; and the last piece, we use two offerings from Akamai. I’m going to talk about them in reverse here. Let’s start with the load balancing property of Akamai. This gives us the logical construct that we call a pool. This is how we group our systems together; and then we have the second property…I’m sorry, so these pools, what we have is a pool per region. We have four main data centers: Singapore, Frankfurt, New York and Santa Clara, California. We have two other smaller ones, one of them is in LA, but they’re dedicated and each one of them are pools of HAProxy systems.
Geo-mapping, because this is a DNS-based system, the geo-mapping ensures that when these requests come in you’re sent to the pool that is geographically as close as possible to where you are.
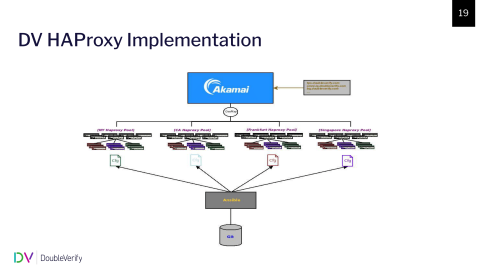
This is a visual of what we’re talking about. All of our applications—and I’ll go further into this in a later slide—are given unique domain names for the URL, but no matter what that is all of it comes into Akamai, and Akamai shifts it to the closest region and that pool of HAProxies in that region is what handles and does the magic. The configs for those pools are pushed out via a central Ansible server. So we control all of our regions from a single place. Within those pools, the config is relatively the same, but not across the pools for obvious reasons, backend servers aren’t the same, things of that nature.

This is a DNS-based system; Every application has a unique domain name, those domains are configured in our HAProxy config, Akamai sends those to the pool, and based off of those names traffic is routed from the frontends to the backends that handle that traffic. To do that we use a combination of ACLs and conditionals to determine where they should go.

This is just an example of how we go about doing that. As you see, we have various domain names come in, we set an ACL, and depending on that we use a conditional to send it to the backend that handles it.

There are a couple of elements that we use heavily to make this happen. To have multiple applications sitting behind the shared set of servers, what we found is because they were once sitting behind F5 they expected certain things, certain things in headers, certain things in the URLs, things like that. So in order to migrate them to HAProxy we had to make sure those things were present when they were behind HAProxy or they were not so happy. We use query manipulation, and header addition and modification, to accomplish smoother migration from F5 to HAProxy.

The second set of directives that we make use of is multi-process CPU mapping, it’s the first of the two. We do this because we want to control performance as tightly as possible; So what we generally do is we take two CPUs off and we say that’s the OS, that yours, go do what you gotta do. All 30 to 60 other processors, depending on the system, are mapped one-to-one to an HAProxy process. This way we’re relatively assured that that processor is doing the work of that process and pretty much nothing else, because we can generally offload most of the OS stuff, most of them, to those other two processes.
This gives us some keen avenues for troubleshooting and insight; If we have a processor burning hot and we want to know why, we find the process pinned to it, we connect to it with strace, and we can tell exactly what that processor is working on. We know the traffic, we can go in and make changes as necessary. It’s just insight we did not have before.
The second one is multi-socket binding; This is our way of now dividing those processes to do specific work, so certain processes will be bound to do HTTP processing, frontend processing, others that will be bound to do HTTPS processing, and then yet another set for backend work. If we look and we see groups of them doing more work than the others and they’re struggling, we know we have to rebalance. If we get to the point where we can’t rebalance, we know it’s time to scale one way or the other.

These are just some other directives that we utilise; I’m sure everyone is familiar with Keep-Alive, HTTP reuse, things like that. We do use the socket-based API, not only to disable/enable backend servers, but we use the stats heavily.

We make use of the built-in stats page, as well as taking some of those stats from the socket and exporting them into Grafana so we can see trends. This has dispelled, I would say, a couple of assumptions that were going on when we were behind F5 because we didn’t have insight. It’s amazing when you pull open the curtain, how you found out that you were running down the wrong avenue, and you were so assured, and it was like, “No, this is what it is.”

So what do we get out of this? We did reach the goal of processing billions of requests daily and, in fact, as of a couple of weeks ago, it’s over 5,000,000,000 daily. We have full redundancy; Not only can we send traffic to any one of our pools if we have some kind of catastrophic issue, but of course, we can stand up new systems to replace the others at will. We stand up pools in a day. Once they’re set up physically in a datacenter and the network connectivity is there, we can stand this up with Ansible in a single day and have our pools ready.
I mentioned that we have datacenters across the world…four basic locations, not across the world yet. We’ll get there. Singapore, Frankfurt, Santa Clara, California and New York. These two kind of go together, and that we can increase and decrease our pools relatively quickly. This is not just for capacity reasons, but when we were doing…we started out with Community edition of 1.8. When we were doing the tests to move to the Enterprise edition, we were able to siphon off groups of these systems and have them working at the same time to do comparison and make sure we had good stability tests. We’re able to do all of these things with our setup.
We can add backend functionality; Now this might confuse you because when I say backend what I mean is our backend applications. So if I have a new web application, I can roll out the config to all of our pools with no customer impact and once we’re ready we turn DNS to Akamai and things work. In fact, we’re usually ready before the developers are. We have our setup good and gone two weeks before they’re even ready to start testing. In fact, we have to remember what we did half the time by the time they’re ready! Of course, with Ansible and Git we can centrally manage our configs, our deployments, all of these.
Distributing functionality across independent systems: What this means is these systems don’t know about each other. There’s a logical construct from Akamai that ties them together, but there’s no way one of the HAProxies knows that there are a hundred other systems like it. So we’re able to spread out our functionality across these systems using this design.

Great! We got out what we did, everything’s done, we can go home, right? No. The first challenge is probably, if you want to classify it, it’s the first-world issue of IT: We have now a wealth of information, what the heck do we do with it? We found out real quick we are not saving logs locally; We filled that disc within a half hour even with logrotate, it didn’t matter. We have Splunk, Splunk licenses do not like that level of traffic.
So for almost the first year, we were missing this insight that we get from logging and we had to figure out a way to gain this access. What we wind up doing is employing RabbitMQ, utilizing named pipes, and having a consumer that polled that named pipe constantly, pulled those messages off that named pipe and sent it into an exchange in RabbitMQ. From there we have the flexibility to do whatever we want with that; We can do anything.
Right now we have multiple things happening simply from that one exchange. We store it all in MySQL so that there’s just an overall store of all these messages. We also have another consumer…sorry, it’s a producer that sent it to exchange, excuse my terminology…but we have another consumer that takes that same set of messages and it sends a subset of that to Splunk, like we needed anyway, the warnings, the errors, the things we need to alert on, things of that nature; but just by doing that—once again open source to the rescue—we’re able to solve some of our challenges.
Unified Config doesn’t seem like it would be a challenge right away, until you have enough disparate web applications behind it and you make a change at the wrong level and affect more than one application. We’ve had to be overly diligent about what we add and where we add it; Most things on an application-specific level are added to the backends, but we can’t do that for everything. Certain information, it’s not available at that level, so we’re diligent about when we add it. When a developer group wants to add something to their app, that’s all they see. Why can’t we do that? Well, there are 20 other apps who will tell you why; We’re responsible to make sure that doesn’t happen. Having a unified config has been a challenge in that we’ve often bandied about should we break this out? Should we have different pools? So far, we haven’t had to do it, but it’s caused us to be hyper-vigilant about how we go about things.

Now, I promised part 2; My dearest friends at HAProxy, when you select an acronym in the IT world, there are ramifications! HAProxy Enterprise Edition, or HAPEE, oh yeah you know it’s coming, tends to not go over so well when you’re announcing in your operator room that you’re doing maintenance for 100 servers. It can lead to something, I’m going to coin this term Pun PTSD.

If you would like examples of that, there you go; There is nothing like every time you have to do an upgrade, a maintenance or anything, announcing that we’re upgrading the HAPEE pools and getting HAPEE puns! If I see Pharrell Williams, he and I will not be on good terms. So I ask you, I’m glad we’re going with HAProxy One, but just as you do great due diligence in putting out your technical work, do the same due diligence for your acronyms and save people like me a lot of headache. Thank you!