
In this presentation, Marcin Deranek describes how Booking.com harnesses HAProxy at a massive scale through an internal Load Balancer-as-a-Service (LBaaS) platform that can easily scale to handle billions of requests per day. Originally, his team used IPVS for Layer 4 load balancing and Keepalived for active-standby redundancy. With their tier of F5 load balancers hitting a ceiling in terms of scalability on Layer 7, they switched to a software-based approach that utilized Equal-Cost Multi-Path routing, anycast and HAProxy. This allowed the Booking.com team to provide LBaaS managed directly through an API called Balancer. These technologies are instrumental in achieving “smart routing”, which provides protection against several failure scenarios that can happen within the network.

Transcript
Hello everyone. Good morning. Over the years, Booking.com has grown from a small start-up to one of the largest travel e-commerce companies in the world. Such growth is good for the business, but at the same time it is a challenge for our engineering teams to scale the infrastructure. Most of the systems designed at Booking.com last a few years, enough for that they need to be re-engineered or re-architected to accommodate the growth. Our load balancing platform is no exception. During this talk I’m going to share with you how we scaled our load balancing infrastructure from a pair of load balancers to hundreds of load balancers handling billions of requests a day internally and externally.
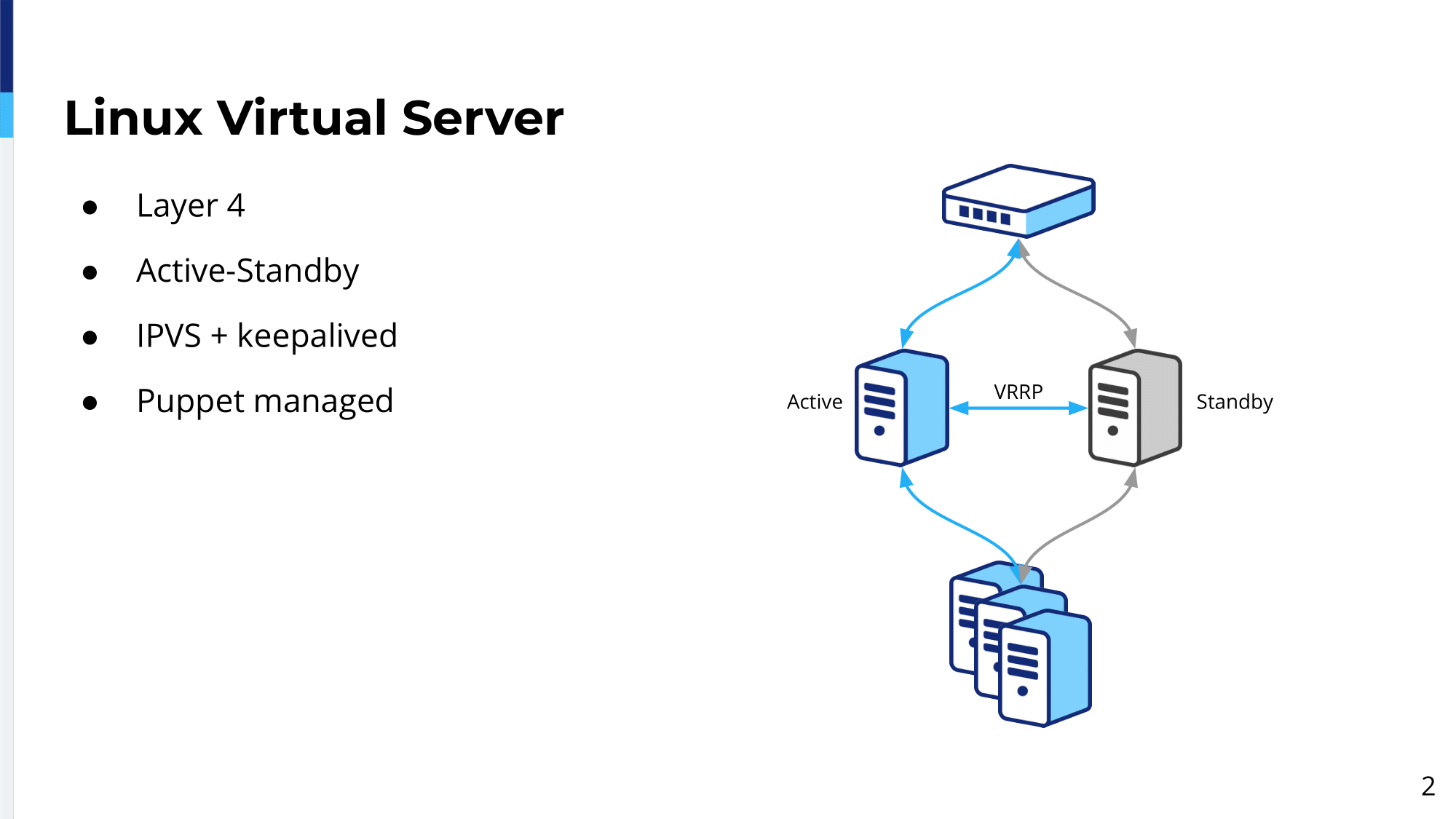
In 2008 when I joined Booking.com our load balancing infrastructure looked like this.
We had a pair of Linux boxes running IPVS, so it’s IP Virtual Server. It’s a load balancing solution in the kernel provided as a module; and for failover we use Keepalived. There was an automatic failover that could take place. Later on, we started actually using Puppet in the company, so these servers were managed by Puppet. Even, I think, our git history still remembers some puppetry around these boxes.
It worked pretty well. We had some problems. For example, ARP caching was one of them. When the upstream basically was caching ARPs and we did failover and the traffic was still going to the old device for some of the site. But overall we were happy with it. The main problem we saw with this was layer 4. Actually, these load balancers were working fine, but we wanted to do more; and that’s why we ended up with F5 appliances, where these were layer 7 load balancers; and layer 7 opened up a whole world of new possibilities, which we liked a lot.
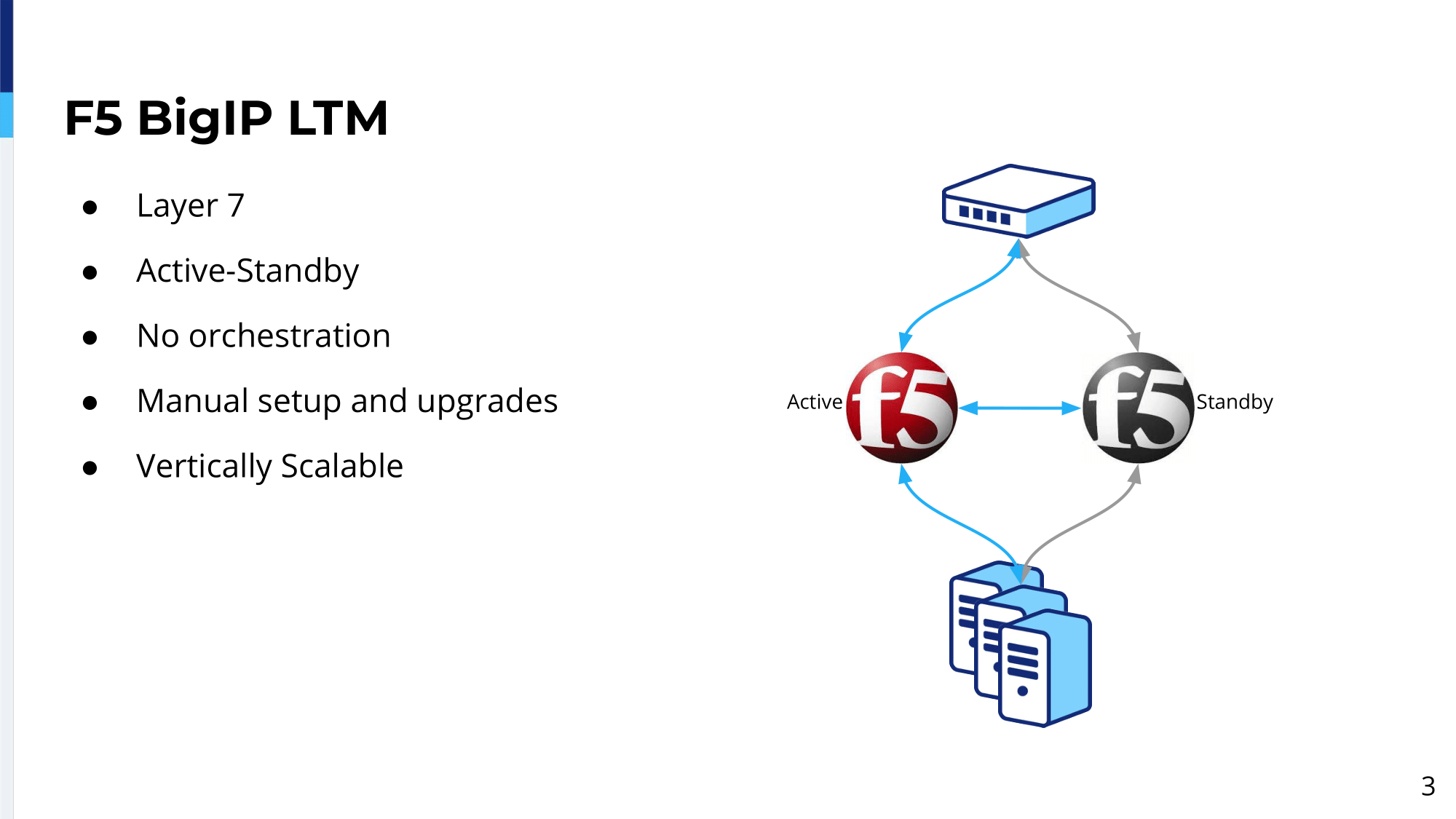
For example, you could alter the payloads, inject headers, remove headers, as well it gave us, like, a possibility of routing traffic. For example, in case of something, some condition, you can send it here or there. Again these devices were active-standby, so one was doing the job. The other was sitting there and doing nothing.
We didn’t have any orchestration around that. Later on, we started using Puppet as puppet proxy, but unfortunately only a certain set of objects on the device. All those objects related to the load balancing itself. Virtual servers, pools and nodes we were able to manage, but device-specific properties like users, let’s say timezone of the device, we had to set them manually. We set all of these devices when they came from…when we purchased them. They had to be manual, and upgrades as well. Especially, at a certain point in time, we had like a lot of vulnerabilities discovered in the SSL etc., so we had to kind of do lots of these upgrades.
These processes were manual. Over time, we developed some scripts and these scripts allowed us to automate some parts of the job, but still there had to be some operator behind it doing the thing. Unfortunately, these devices were vertically scalable. When our traffic was growing for the site, we had to buy bigger devices and over time we ended up with this.
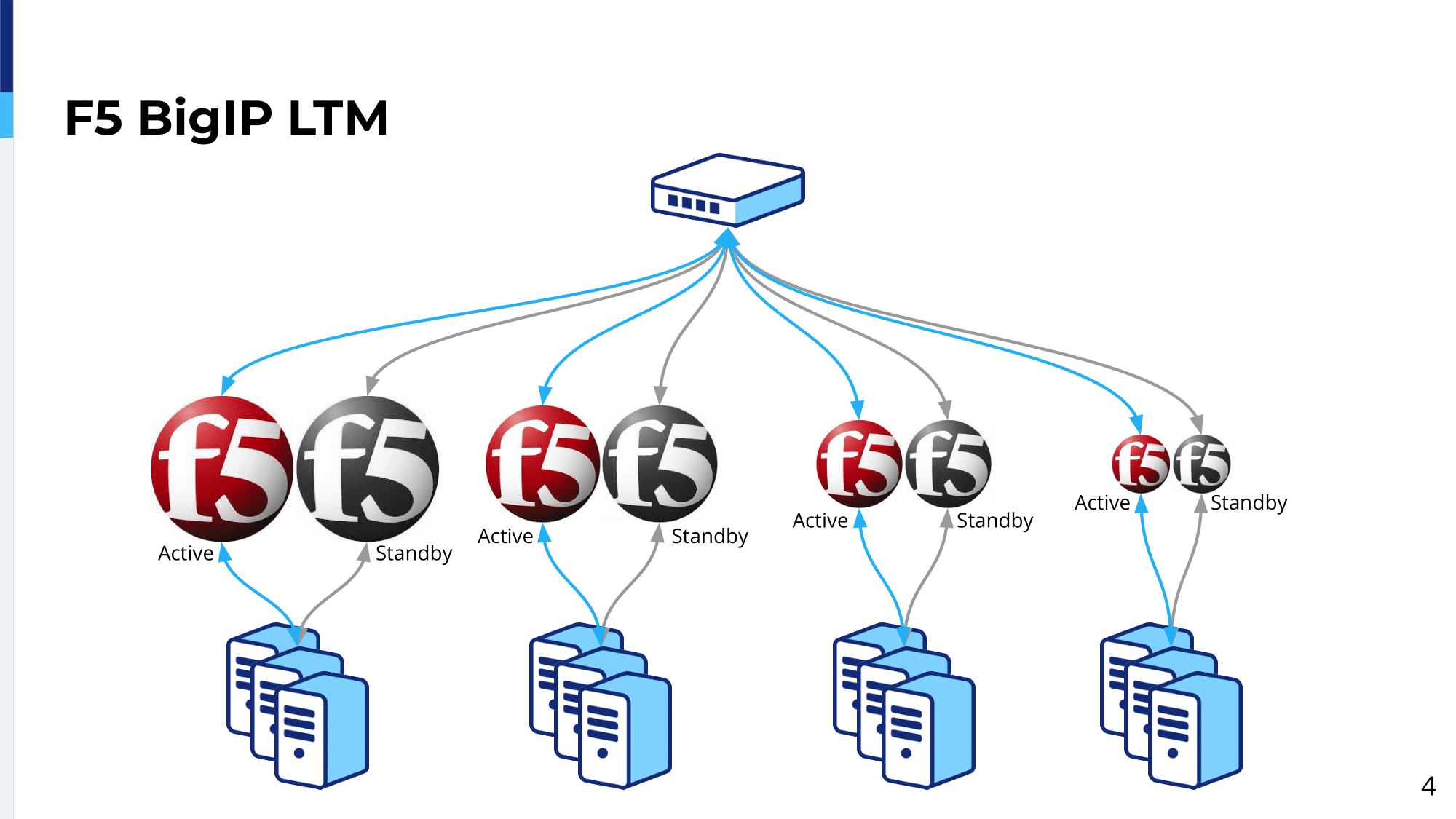
Essentially, we had a lot of different pairs of different generations of hardware. The way how it worked was, usually, the traffic for the main site was growing, so we had to buy a new pair of devices. We were buying those, the most powerful, the most expensive ones for the main site and those which were currently used for the main site were repurposed for some other lower traffic sites. At the time, we ended up with all these generations, lots of this hardware lying around; and we hit, at a certain point, that we had already kind of reached the sort of top-of-the-line where there was no room to grow up. And actually, the VPN solution from F5 we didn’t actually, we didn’t like it a lot. So we started…we did some research, and we thought, there must be a better way of dealing with the problem.
Equal-Cost Multi-Path Routing
We came across the Equal-Cost Multi-Path routing.
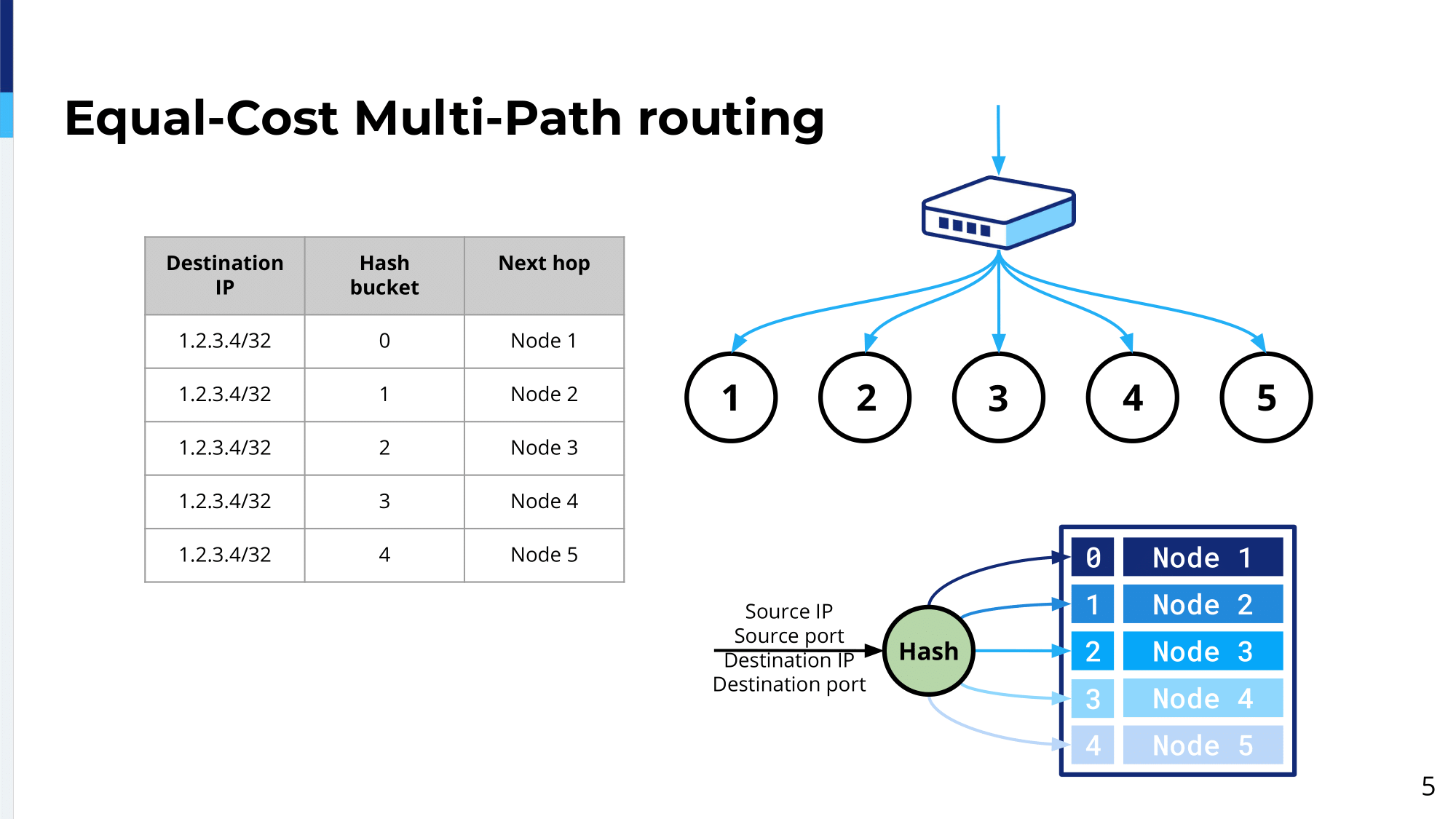
Equal-Cost Multiple-Path routing is a strategy for routing network packets along multiple paths of equal cost. When forwarding a packet, a router decides which next hop to use based on the results of the hash algorithm. In our case, we use per-flow load balancing to ensure a single flow remains on the same path for its lifetime. In this case, the flow is identified by source IP address, source port and the destination IP address and the destination port.
An interesting thing happens when the amount of nodes changes. In this case, some of the flows will get reshuffled; they’re going to change their path. Depending on the different implementation of the hash algorithm, ideally you want only 1-Nth of the flows to change their paths because let’s say you have four nodes and let’s say one of them died or you take it for maintenance and then, only 1-Nth, so the flows that would go through the node number five would get reshuffled to the other ones. And actually, some vendors actually provide this. Unfortunately, some other ones, at least at the time when we tested it, many more flows get reshuffled. Depending on this hash algorithm implementation you might want to check it before you go on. You want to buy some, likely, you go on shopping.
ECMP was…we like it a lot because it allows you to do load balancing at the line rate. I suspect it’s mainly due to that there’s no session table, right? Usually, it was the problem of F5, there’s a limit of this amount of sessions, etc. Whenever the sessions go up, the things get slower and slower. In this case, you have a constant speed because for every packet you apply the hash for the packet.
This is how our architecture in one availability zone in a single environment looks like.
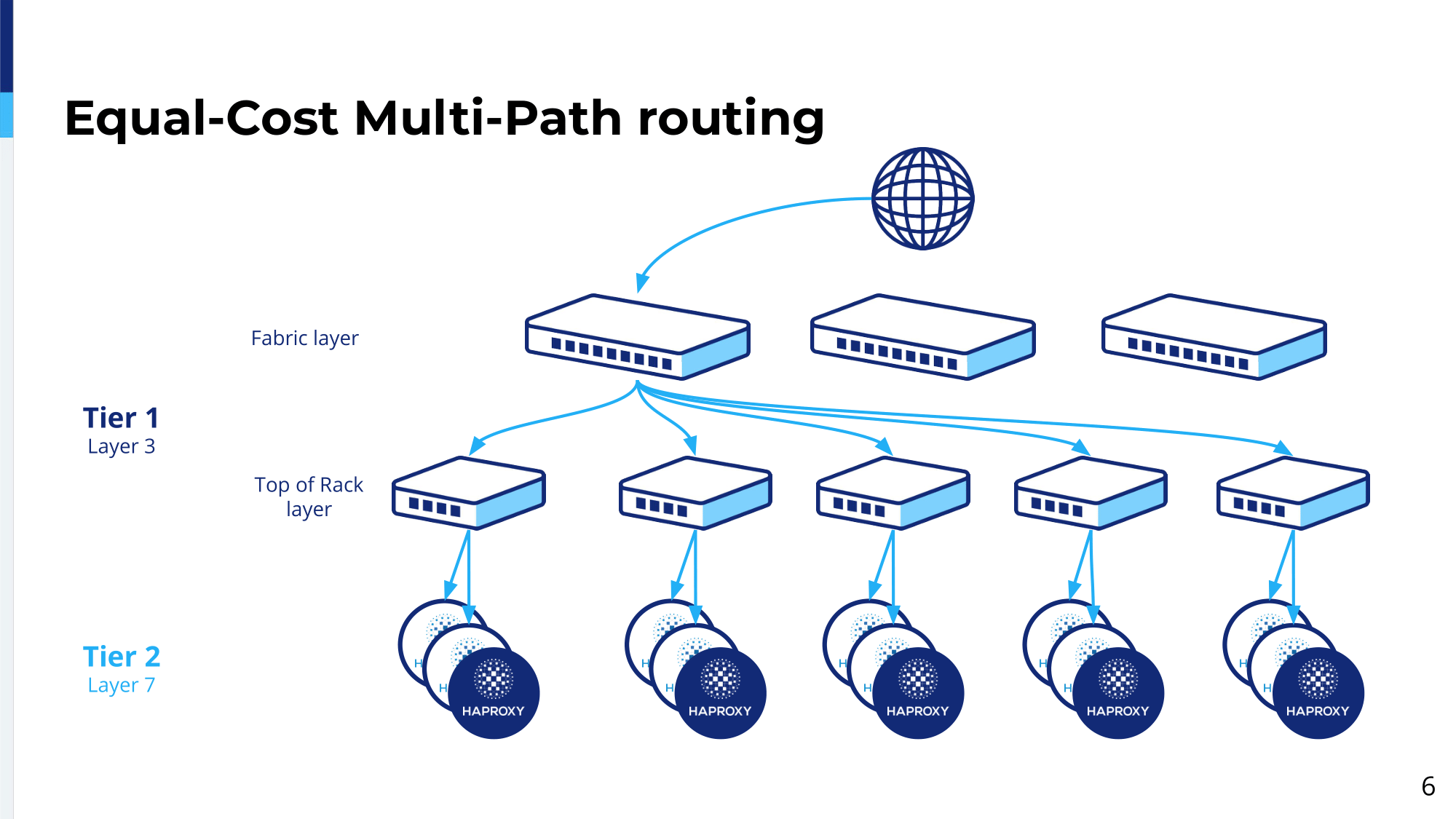
We have two tiers. We have a layer 3 tier and a layer 7. Traffic comes from the Internet. It hits one of the fabric layer switches. A single IP address, by default, is assigned to a single fabric layer switch, even though when this switch dies the other switches will take over automatically. This one is a primary, but if this one dies, then the flows will get automatically handled by different fabric layers switches.
Then when the traffic hits the fabric layer switch, then the fabric layer switch will round the hash algorithm on the flow and will have, because it has five alternative paths, and it will select for what traffic to one of the top-of-rack switches. And then, again, when the traffic hits one of the top-of-rack switches based on the hash algorithm of the flow, it will have two alternative paths because we have two HAProxy load balancers behind it. Then it will, based on the hash result, it will forward it to one of the F5…sorry, the HAProxy load balancers.
In our architecture, we have different load balancer groups. On the diagram there, they are presented as blue and white HAProxy logos. The load balancer group is a set of load balancers, which is configured in exactly the same way and they handle the same set of sites, the same set of IP addresses. Creating such groups allows us to isolate certain sets of sites from each other. Let’s say that something bad happens to a certain load balancer group, it will only affect this load balancer group and not the others.
Obviously, it’s possible that a single IP address, even though we don’t do it by default, is handled by two load balancer groups, but usually we do it when we transition, let’s say, one site from one load balancer group to the other. For temporary, it will run through two groups and two groups will handle the traffic.
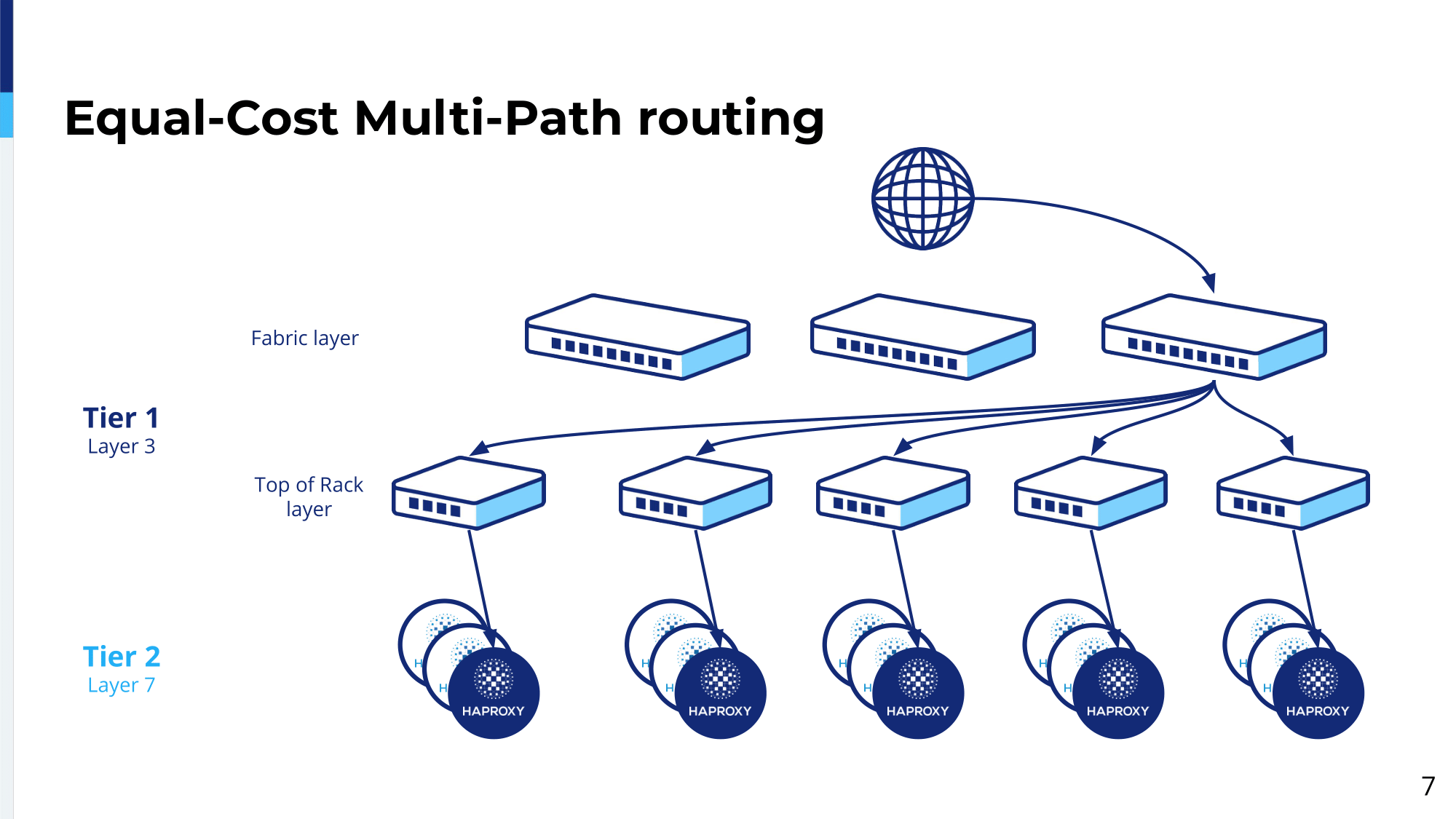
In this example, we use the, for a different site traffic goes to a different fabric switch. Again, the fabric switch will have five alternative paths. We use exactly the same top-of-rack switch infrastructure. And when it hits the top-of-rack switch, the top-of-rack switch will forward to the blue HAProxy load balancer.
Anycast
We use Equal-Cost-Multi-Path routing in combination with Anycast. Anycast is a process for routing network traffic where sender traffic is sent to a destination that is closest to it in terms of network topology. Closest could be defined as lowest cost, lowest distance, smallest amount of hops, or potentially lowest measured latency. In practice it means that, essentially, a client goes to the endpoint, to the load balancing platform, which provides the lowest latency. We prefer locality. You always go local, unless the local is not available, you go somewhere else, which is the closest.
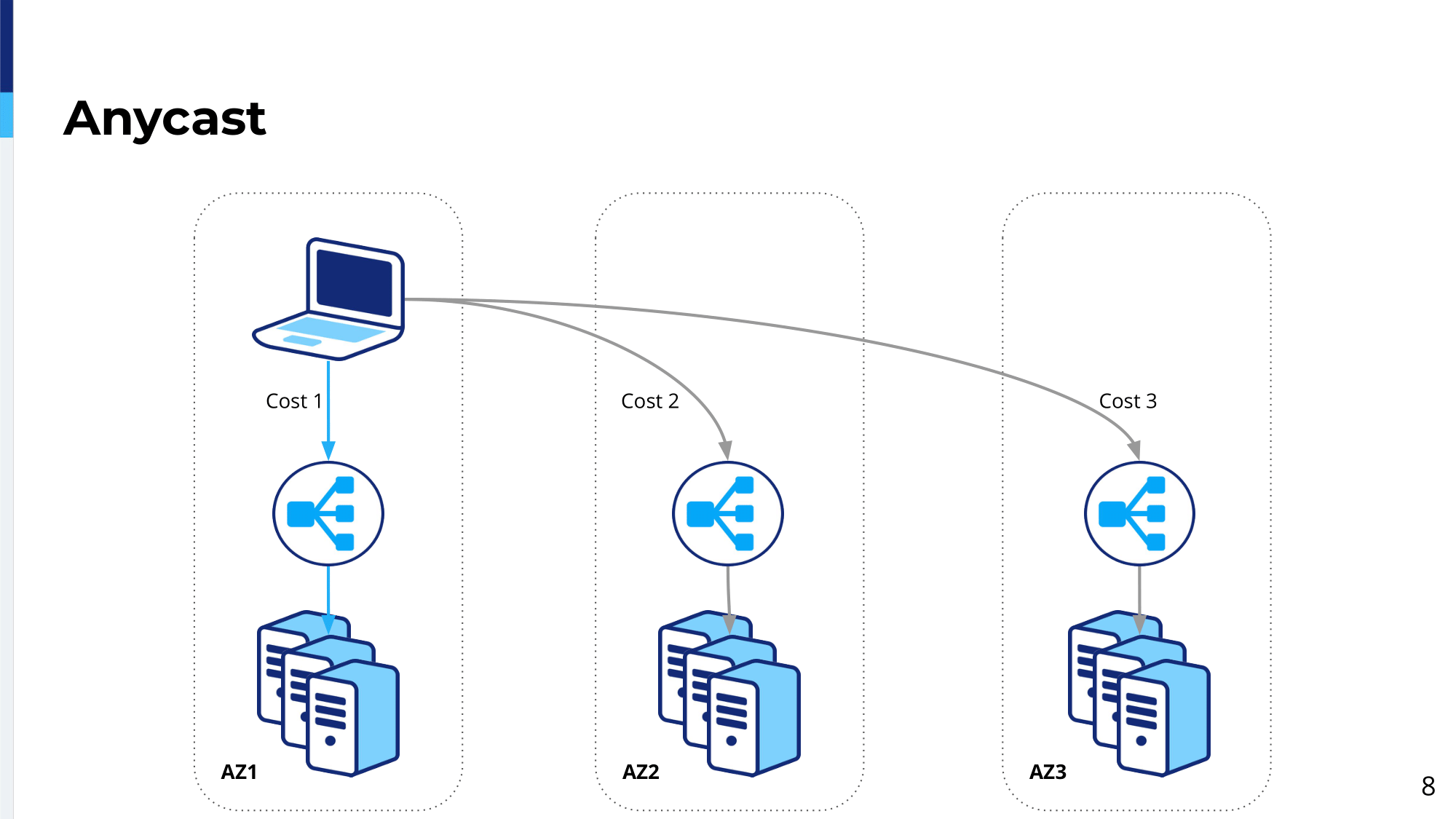
In this example we have a client in availability zone 1 and because of the lowest cost, it will go to the load balancing platform which provides the same service as other availability zones, and then it will be handled by the service in the same availability zone. So it provides the lowest possible latency.
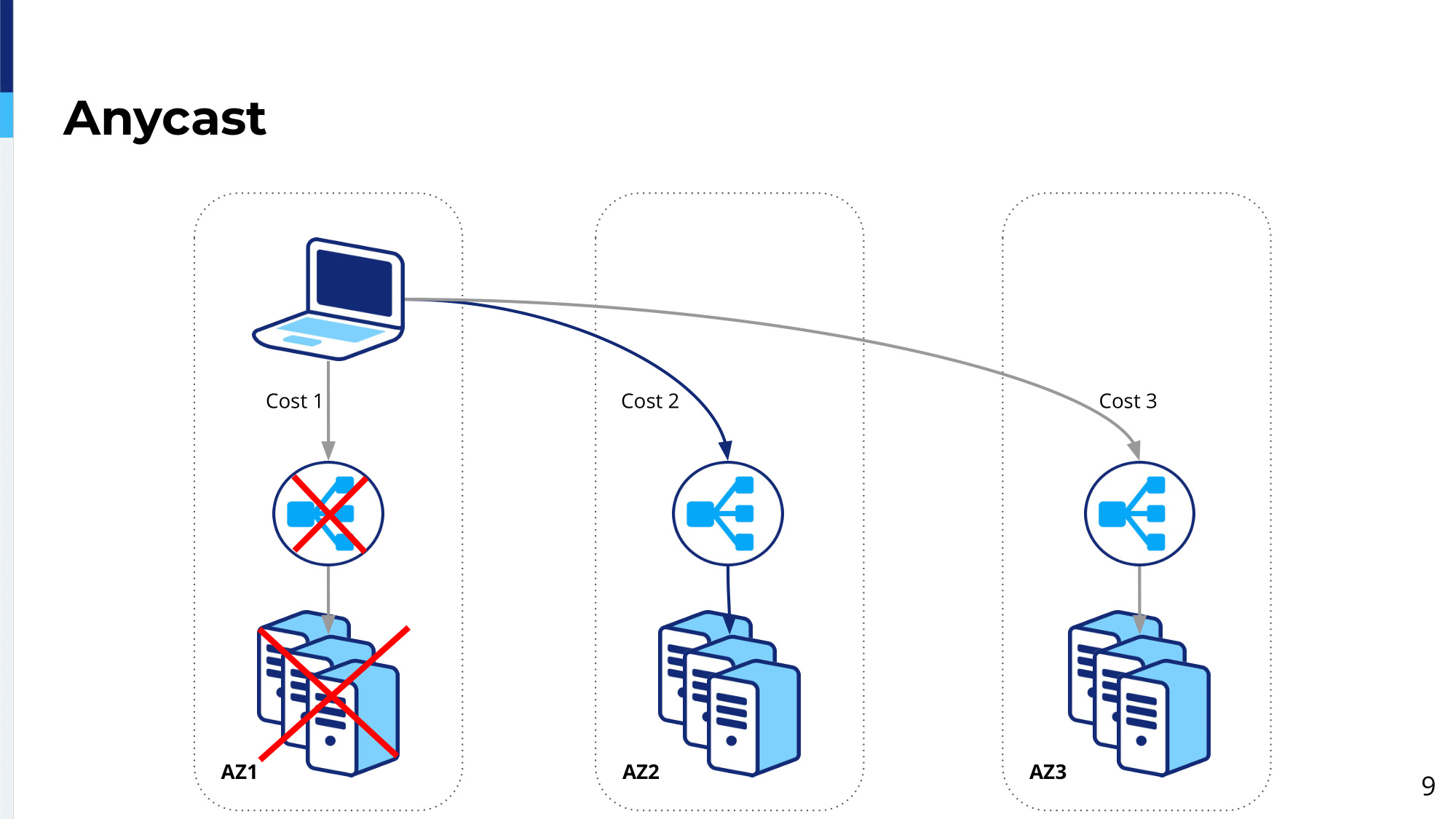
Additionally, when, let’s say, the load balancing platform goes down or it’s not available or the load balancing platform is down there, then it will choose the next closest availability zone, servicing with the cost 2, in our example. And it will be handled by load balancing platform in availability zone 2 and the servers there. This will provide us automatic failover and resiliency of our service.
Balancer API
This is our architecture and the data plane. To manage that we’ve built our own software. We call it Balancer.
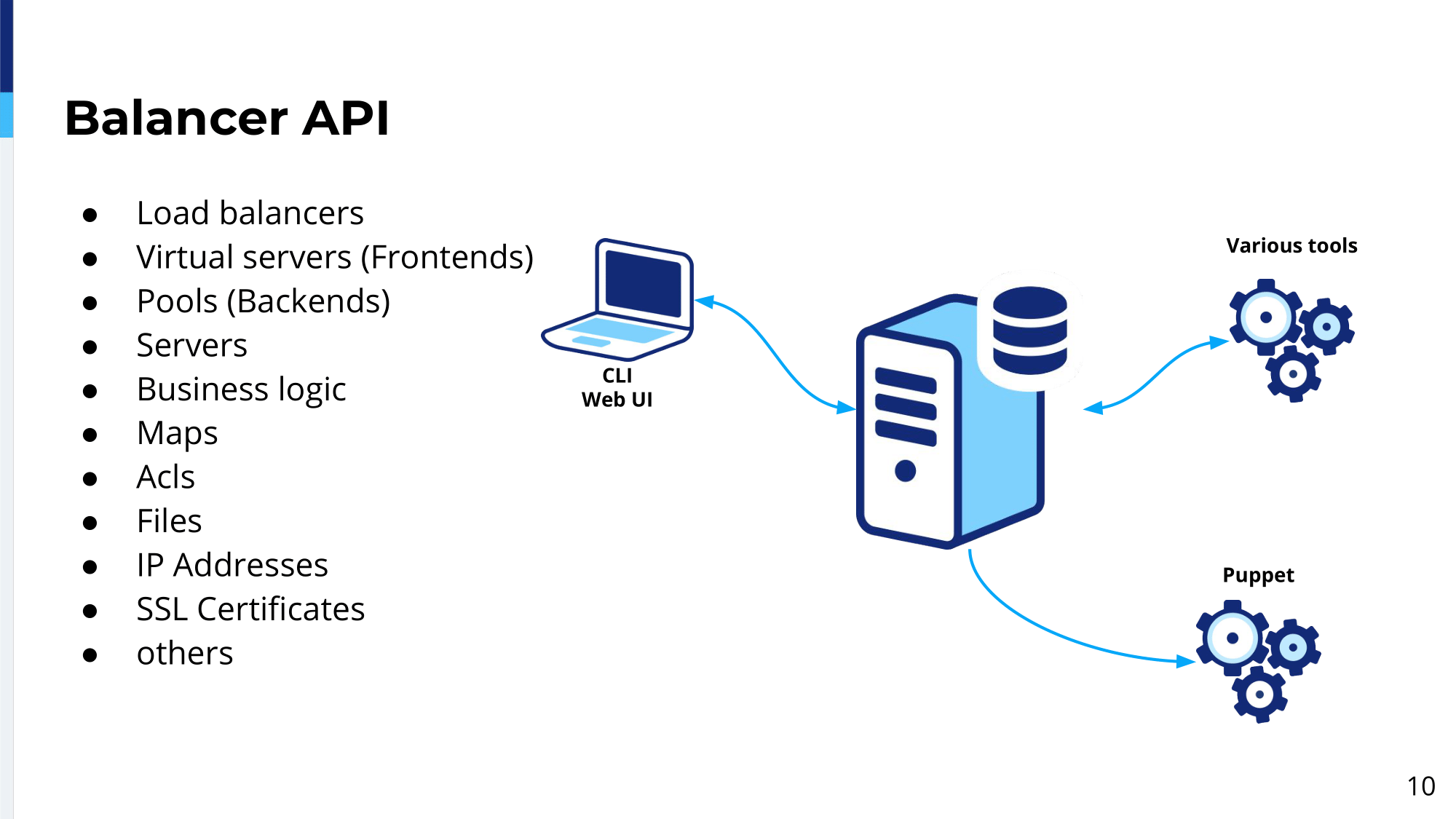
This software is used to manage our whole load balancing platform in the whole company. Obviously, we have different clusters to handle different environments, but this is the same piece of software. At the center of this software we have Balancer API, which essentially stores the whole configuration in the database and the configuration is stored as objects with attributes, and as well with a relationship between those objects.
For example, we have load balancer objects, which correspond to the physical load balancers. We have virtual servers, which correspond to HAProxy frontends. We have pools, which correspond to HAProxy backends. Servers. Business logic is a snippet of HAProxy configuration which can be assigned to either a virtual server or pool; and some of this business logic can be context aware. So depending to which…in which context it gets assigned, to which virtual server it is assigned, it might do slightly different things.
For example, if it gets assigned to virtual servers it can actually deal with different…it will actually use different sets of pools, a different set of backends. Basically, you build, like, one logic and you can assign it to different virtual servers and will do certain things depending on which context it is assigned. It will actually figure it out itself. Maps, access lists and files, or data files. We store data there and they can be used by business logic. IP addresses can be assigned to virtual servers and SSL certificates as well we manage there, or can be assigned to IP addresses and there are other values like smaller objects.
Service Discovery and Registration
How do servers and load balancers get configured?
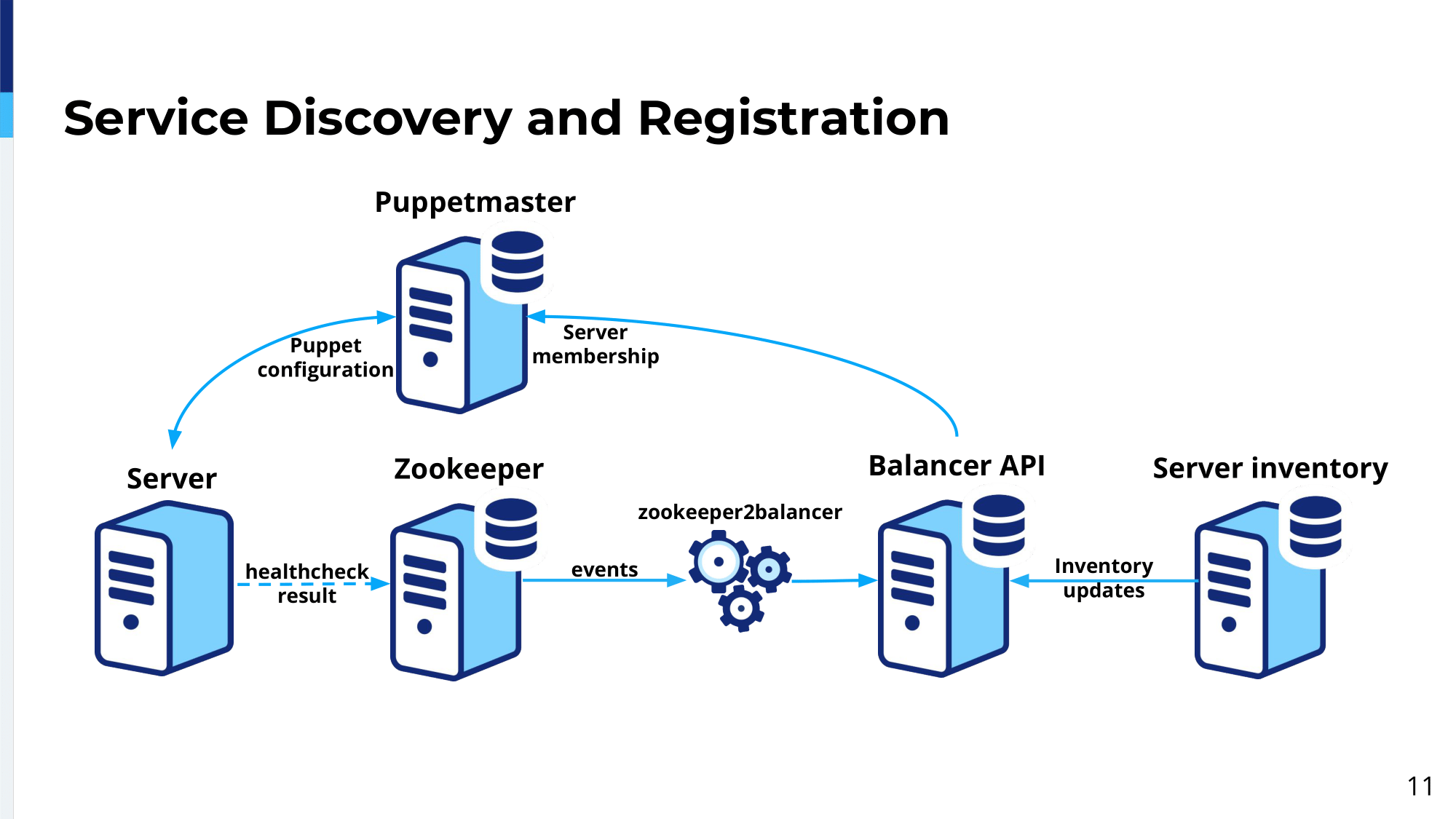
This diagram describes basically the whole flow of how the server essentially ends up in the configuration, how the server gets from the point when it gets provisioned to the time, to the point, where it actually gets traffic. Our servers are kept in the server inventory where, basically, some of them are racks available for use; and somebody basically comes and wants to provision one server to be a web server to handle traffic for a specific service.
Somebody comes to the user interface and clicks that I want to provision this server as a web server. At this point, the server inventory will send an inventory update to Balance API. This is our brain for our load balancing platform. In this inventory update, we will get the name of the server and some attributes like IP address of the server, and also, as attributes like name of the potential class that the server belongs to, the roles it belongs and the availability zone.
Every time we provision a server we don’t want to manually go to every pool and say, “Add this server here, add this server there.” The way how we solve it is by when we create a pool we give it a specific set of attributes like a role, availability zone, and potential clusters, and these attributes you can think about like a set of rules. If this newly provisioned server, an inventory update is sent to the Balancer API, and these attributes of the back of the pool will match the attributes of the server. The server will get automatically added to the pool.
We want two things to happen automatically: Every time some new server gets provisioned, it will automatically get the pool, the relevant pool it’s supposed to be in. When the server gets added to the relevant pools in the Balancer API, then the server gets provisioned. Operating system gets installed and then Puppet kicks in to configure the server. At this point, Puppet will request configuration from Puppet master and Puppet master, on behalf of the server, will request server membership for specific pools the service is in and then it will configure Zookeeper agent, which will run on the server.
The role of the Zookeeper agent is to make sure the service provided by the server is okay. So, the server is healthy. The server can handle live traffic. Zookeeper agent will run on the server and then once it makes sure the server is healthy, it will register to Zookeeper under a specific namespace, which was configured by Puppet. This namespace is watched by Zookeeper to Balancer. It’s a separate daemon, which acts as a proxy between Zookeeper and Balancer API. Essentially, it proxies the information from Zookeeper into the Balancer API. Once it will see the internal node or the specific server in a specific namespace, it will enable this server in the Balancer API for specific pools. At this point, the server gets enabled.
Initially, when the server gets inserted through the server inventory the server is disabled by default, for a good reason. We don’t want any server to get traffic by default, right? We only want it to get traffic when we confirm it’s healthy, everything’s fine. At this point, the information gets propagated through Zookeeper and then Zookeeper to Balancer will enable it. At this point, the server is ready to receive live traffic. Similarly, when the, say, health check fails or server goes down, then the internal node gets removed from Zookeeper and then this information gets propagated to the Zookeeper to Balancer, and Zookeeper to Balancer will remove…sorry, will disable the server in Balancer API.
Load Balancer Configuration
This is how the information is stored in Balancer API, but how does this information get propagated to the load balancer?
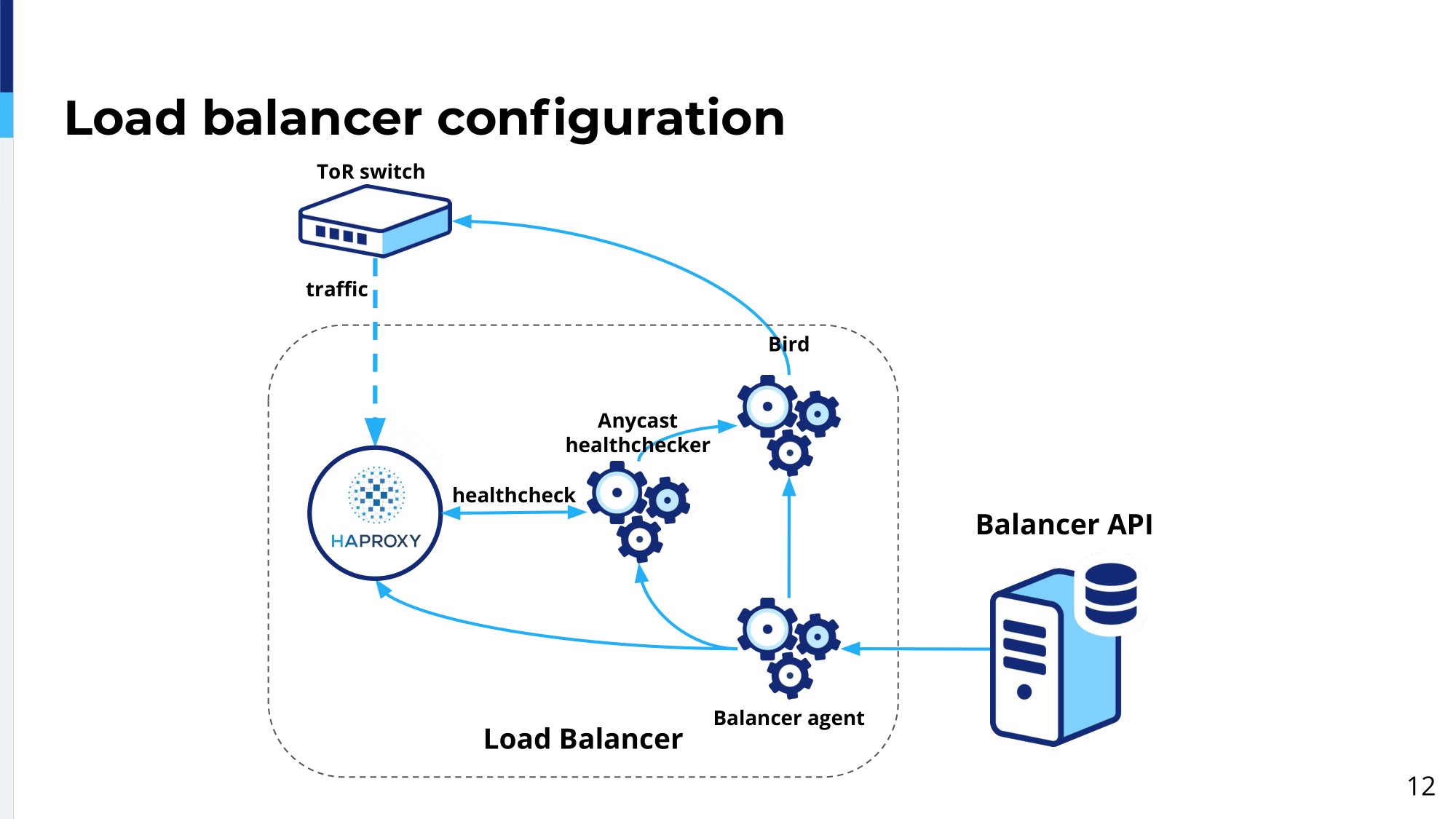
On every load balancer we run a Balancer agent. The role of the Balancer agent is essentially to configure all the components and get configuration from Balancer API and configure relevant components of our load balancing platform. In this case, the Balancer API will periodically check for configuration changes and will first configure HAProxy, HAProxy software.
It will configure it. The configuration can take place in two ways. If the configuration change can be applied over the socket at runtime, it will do that; and then you will update the configuration file. If the configuration is not supported over the socket or there are too many changes, for example, a hundred whatever, it will fall back to the reload. So, update the file and then schedule reload of HAProxy. Once the HAProxy gets configured with all the relevant services, Anycast healthchecker will get configured.
The role of the Anycast healthchecker is to essentially make sure that all the services which are configured on HAProxy are healthy. Actually, it will check all the services behind a single IP address. Once all the services, because behind a single IP address we can have multiple services…let’s say we can advertise we can provide HTTP/HTTPS or, in some cases, we provide SSH for example for, like, for Gitlab, for example. In this case once the Anycast healthchecker will confirm all services behind the single IP address are healthy, it will reconfigure a Bird, BGP Routing Daemon, and Bird will start announcing this IP, this prefix or this IP address to the upstream. In our case, it’s a top-of-rack switch. Then when the top-of-rack switch will receive this advertisement, all the traffic will start flowing for this specific IP address to HAProxy load balancer. This is our load balancing…then HAProxy will forward this traffic to the backend server. This is our load balancing platform.
Visibility
We need, as well, a good visibility of that. We have extra daemons running on the load balancer to make sure we have good visibility of what is happening.
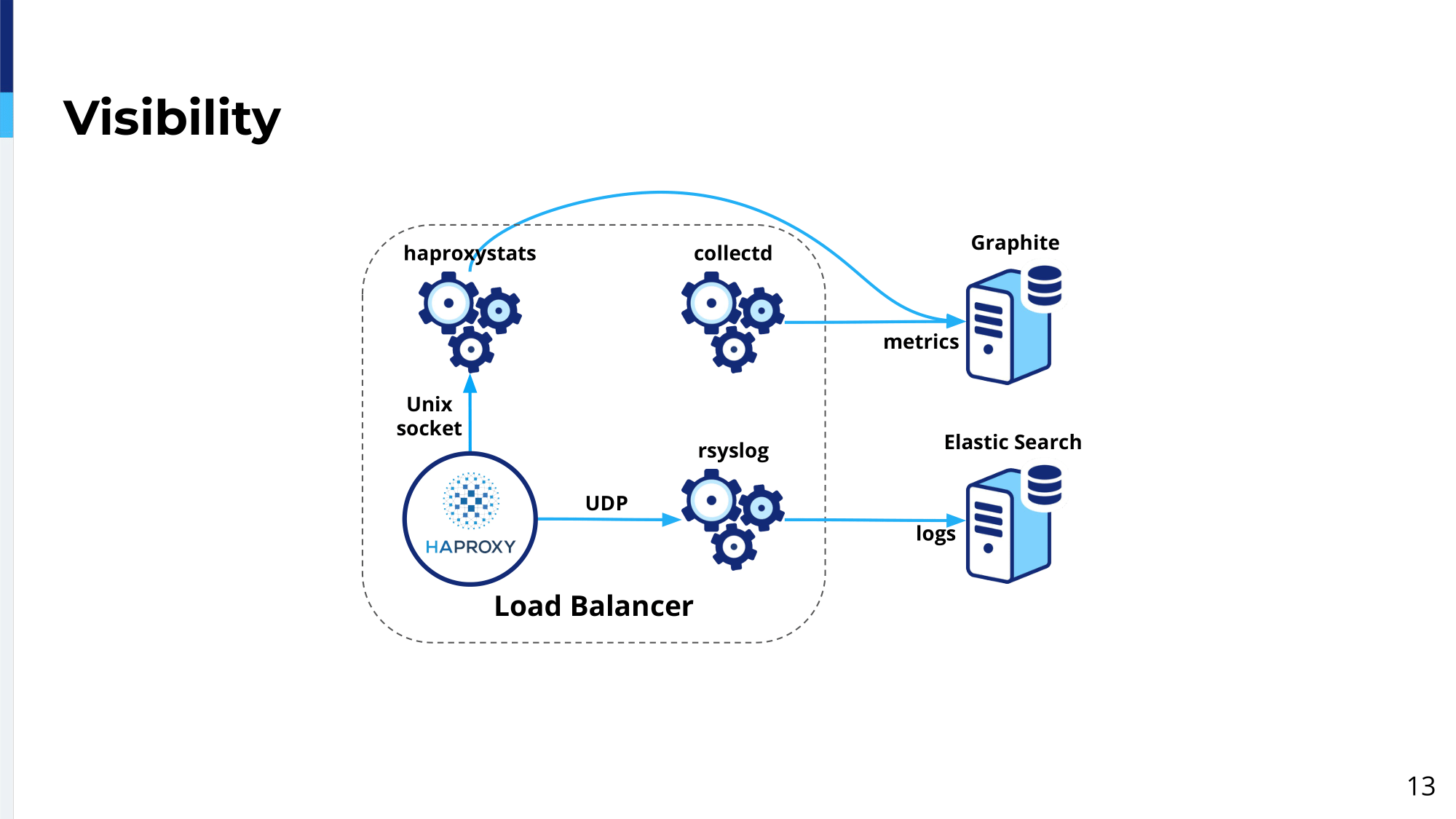
We have created haproxystats demon, which periodically dumps the information from HAProxy over stats socket and will submit it to Graphite. Similarly, Collectd is running on the box itself as well to collect operating system specific metrics and submit them to Graphite. These metrics can be used, for example, to build some nice dashboards or to set up some, let’s say, Bosun monitoring if certain metrics go below a certain threshold, etc.
Additionally to Graphite metrics, we send access and error logs to Rsyslog, over UDP obviously to not block; and then Rsyslog, local Rsyslog will forward these log messages to a central logging system and then eventually they’re going to end up in an Elasticsearch cluster where they can be analyzed and then we can build some visualization, do troubleshooting, etc., because then we have our own per-request logs.
Based on the data stored in Elasticsearch, essentially we can see different things. It’s up to you to decide what you like to see there. HAProxy has plenty of different features so what you want to actually dump there it’s up to you. There’s lots of data.
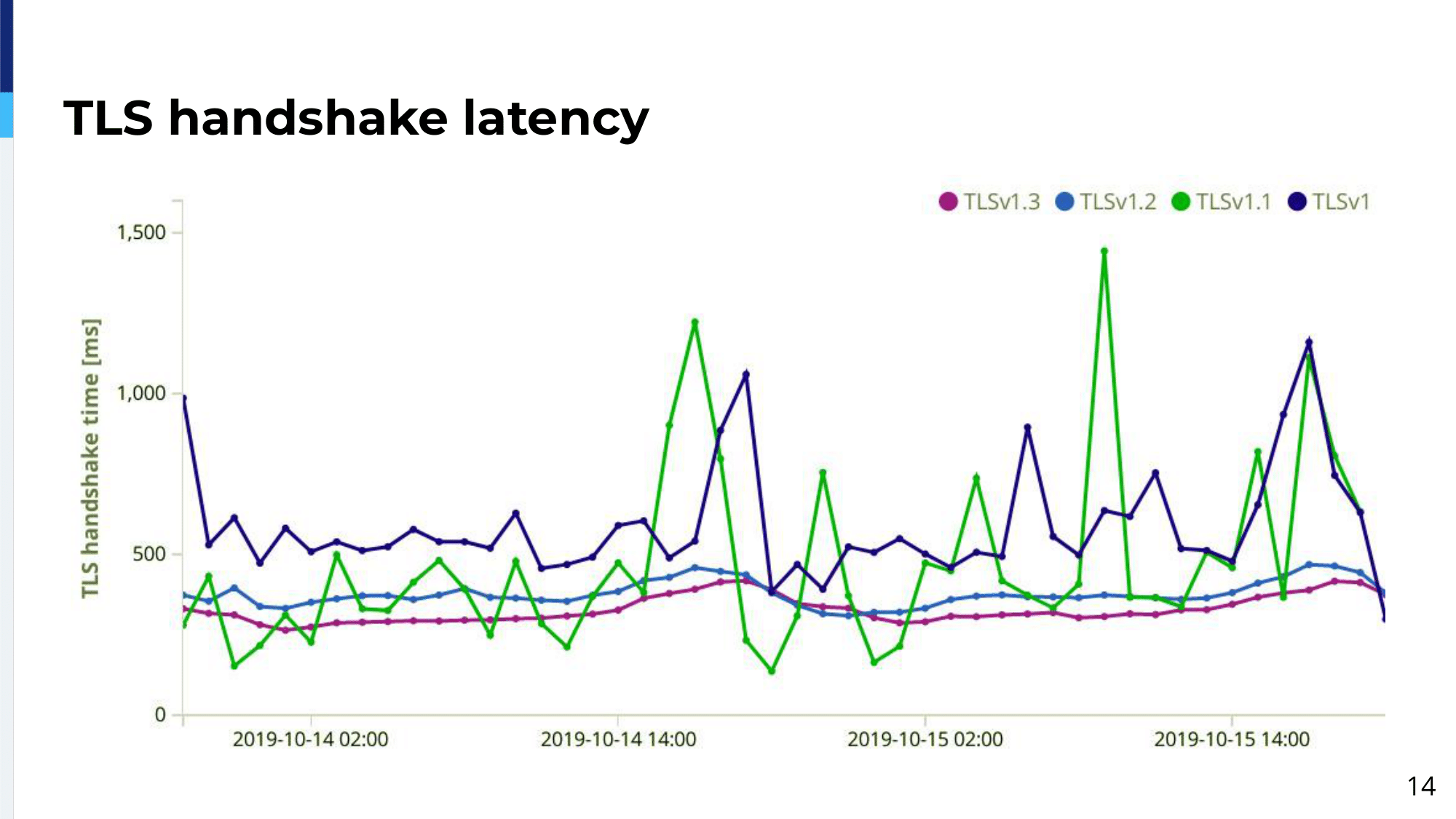
In our example, you can see that, you can compare different TLS, what is the TLS handshake time for different TLS versions. The variability for TLS 1 and 1.1 comes from the fact that actually the majority of traffic these days uses TLS 1.2 and 1.3 and we don’t have enough samples for TLS 1 and 1.1 and that’s…the graph is a bit jumpy. Additionally, you want to make educated decisions based on the data you store there: whether you want to enable TLS resumption or not and how much gain you can get from enabling that.
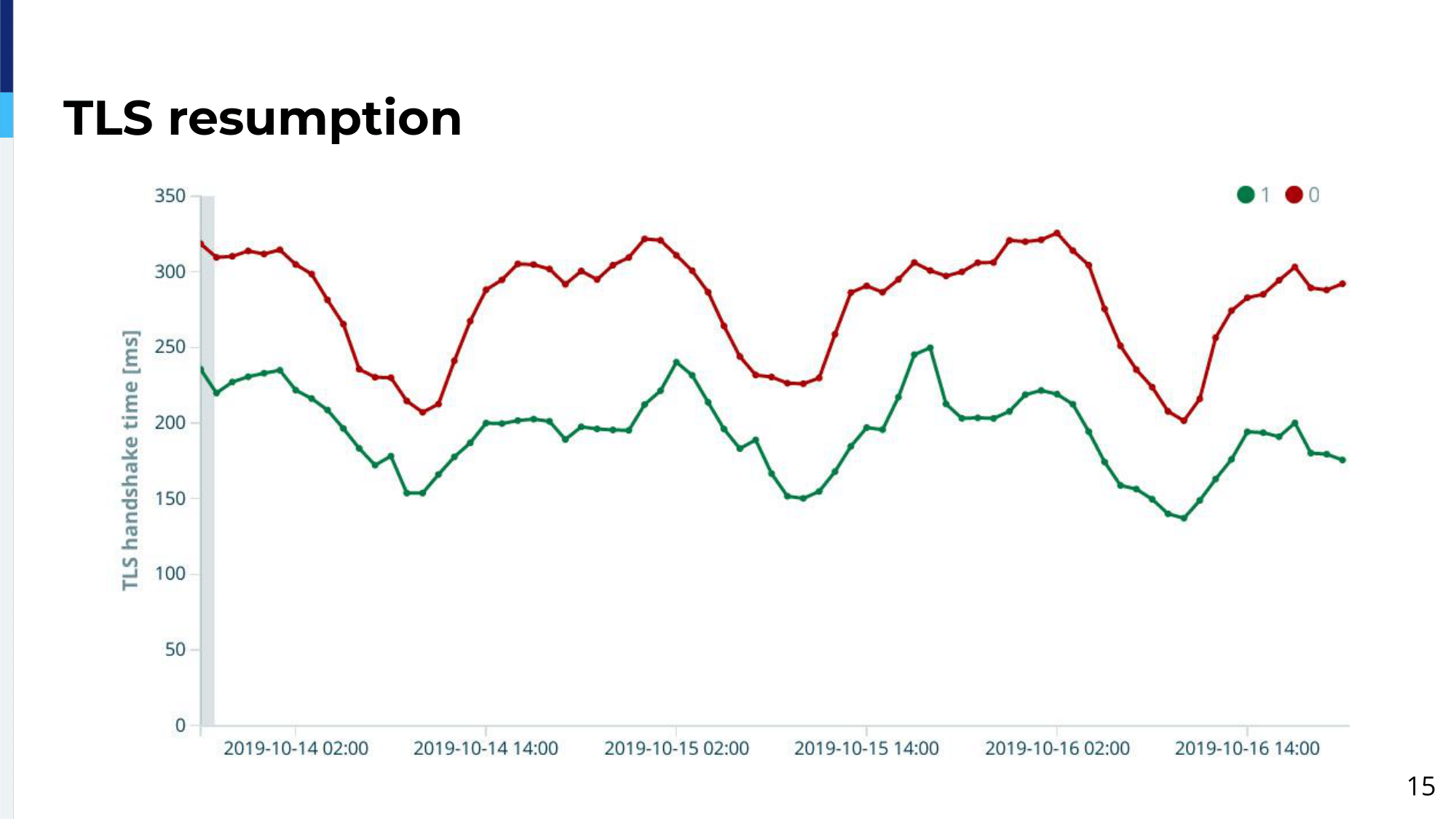
Additionally, you want to make educated decisions based on the data you store there: whether you want to enable TLS resumption or not and how much gain you can get from enabling that.
Balancer UI
At Booking.com we aim to provide load balancing as a service.
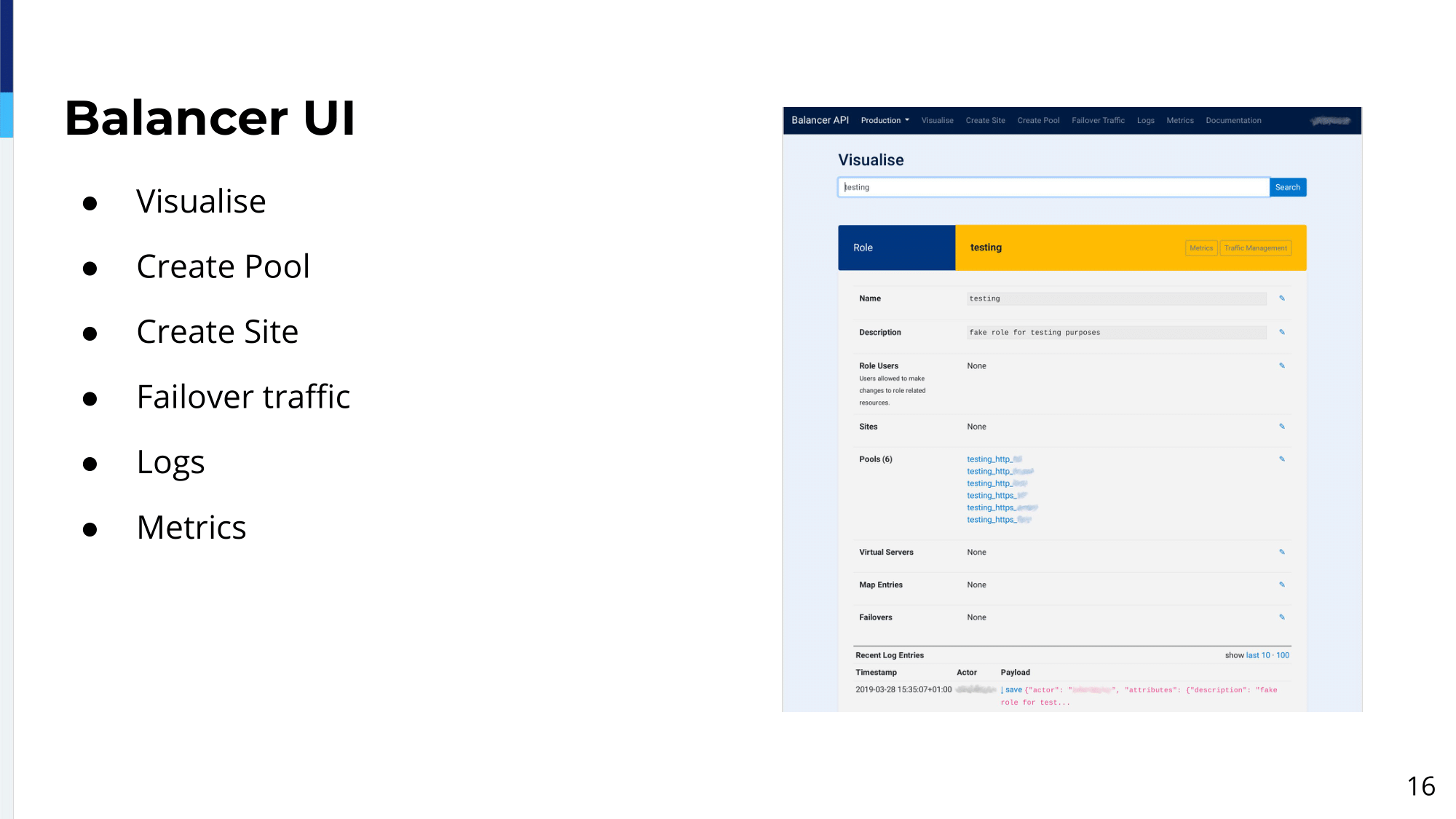
That’s why for the balancer we create multiple user interfaces, so people who don’t know much about load balancing can actually use our service, our load balancing platform. The first user interface we created is a visualisation tool. You have a screenshot on the screen. This user interface allowed people to actually see how the configuration looks like. So, basically visualize it and as we click on the relationship, then they can see how the objects are connected. If they can find an object, then they can kind of follow the relationships.
As well, we allow them to change attributes. They can actually modify the configuration at runtime. They can go there to the UI and then just send like a changing ratio or whatever. They can do it. Obviously, we limit the scope of the actions to the roles they maintain. They can only manage their own services.
We also created the “Create Pool” and “Create Site” user interfaces—I’ll talk about it in a second—which they allow them to create a configuration for the newly built services. Additionally, we created a failover traffic user interface, failover traffic is for, basically, easy failover of traffic between different availability zones in case of an outage or bad rollout or servers being down. So, in a very easy way, basically, they just click one button and that traffic will just get away from certain availability zones. We also provide them access to logs and metrics. If they want to troubleshoot a problem regarding their service they can go directly to the data or if they…we provide a set of dashboards, like generic dashboards, but if they want to build their own dashboards with custom stuff, we provide access to metrics directly.
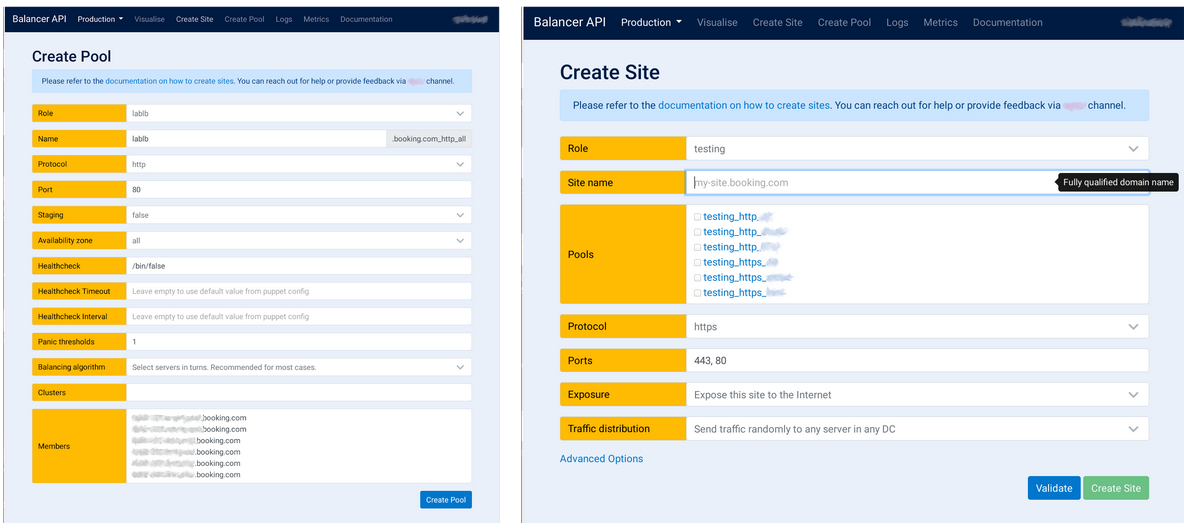
For the role owner to create their own service first they need to create a pool. First they have to specify a role. The most important attributes is a role, availability zone, and potential clusters. These three attributes will describe which servers are going to end up there. Once the user selects that in the Members field, he will see which currently present server in the server inventory will actually end up in that pool. If he’s happy with the results, if actually this server should be there, basically he will click the Create Pool button and the pool gets created.
Once he has a pool then he can proceed with the Create Site user interface where he first has to select the role for which he wants to create a site; by site I mean that’s like multiple virtual servers which are configured in multiple availability zones at the same time. So basically the available…let’s say through our infrastructure. Then once he selects a role, he can select the pools he wants to use for that site, some other managed for attributes, and then click the Validate button to actually validate if he’s happy with the changes which are going to take place. If he is happy with that, he clicks the Create Site button and his site gets created in a short while. He basically can just use it right away.
Smart Traffic Routing
One of the biggest features, which we developed on top of HAProxy, which was actually developed as context-aware business logic, is smart traffic routing.
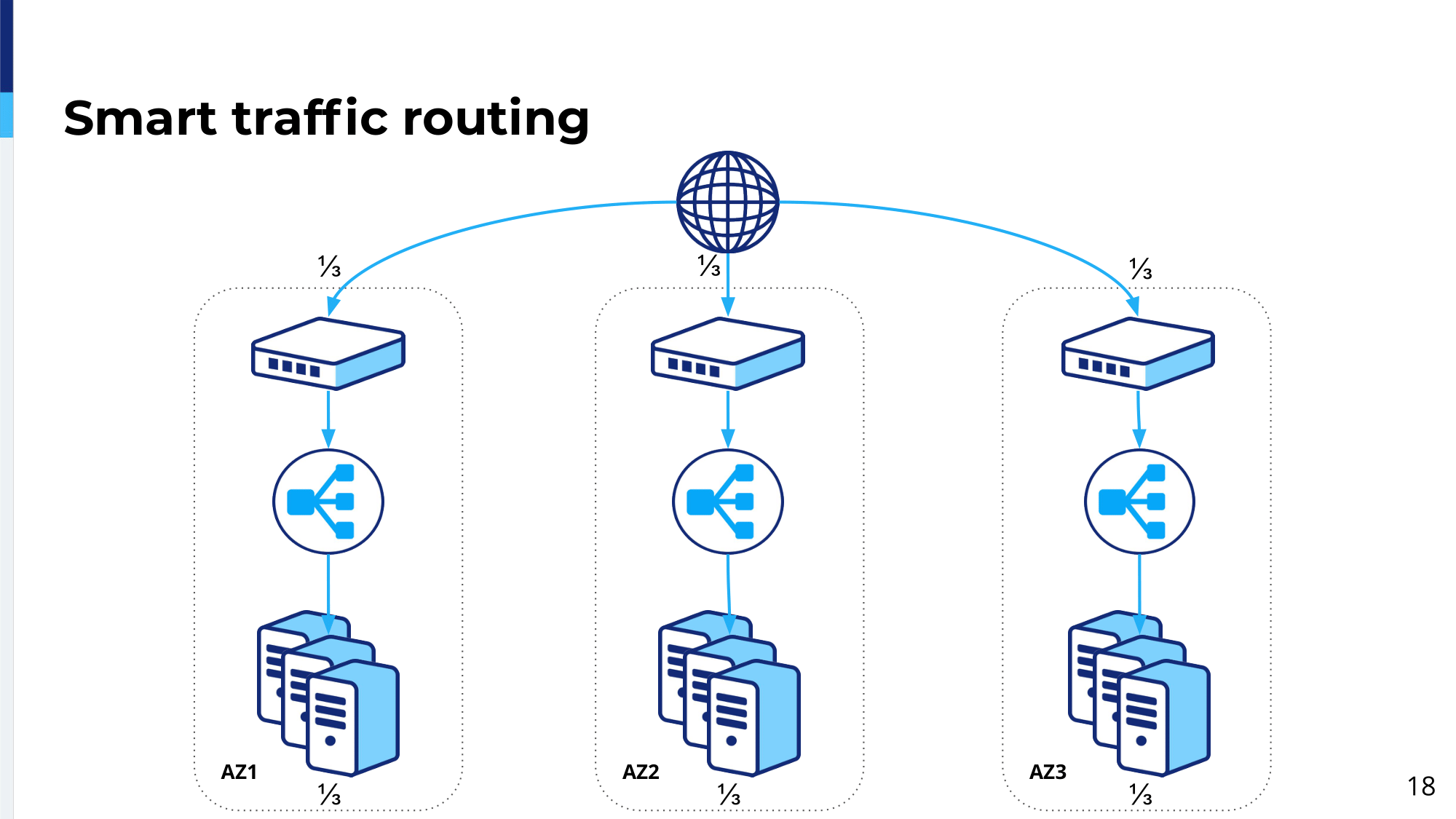
Smart traffic routing is business logic which has three requirements in mind. The first requirement is that we want traffic to be delivered whenever possible. Obviously, we prefer always to go to the local server. Due to the lowest latency we always prefer a local availability zone or to go to the local, let’s say, local servers; but if that’s not possible, use the servers wherever they are, which I don’t care which availability zone. Please deliver traffic to those servers if they are healthy. It’s always better to serve slow responses rather than returning errors to the customers. We aim to never fail.
The second requirement is that we always want even traffic distribution between different availability zones. This requirement comes from the fact that if you’re dealing with lots of servers, then actually every…if Availability Zone 1 in our example goes down and then Anycast will send it to the next closest availability zone. In this case, it will be Availability Zone 2. That means this availability zone’s servers will receive twice as much traffic. If you would evenly distribute it between the remaining availability zones, these servers would, or all servers would only receive 50% of the traffic. If you’re dealing with a lot of servers, 50% versus 100% means a lot of hardware. This requirement tries to actually more efficiently use your hardware and have lower capacity requirements for every availability zone.
And the last requirement is that we want our clients to stick to a specific availability zone. This requirement comes from the fact that…is due to the session data because when the client goes to…hits specific servers in a specific availability zone, his session data gets stored locally and, as well, it gets synchronized to the other availability zones. If he will flip between different availability zones on per-request basis, there is a race condition between the data being copied…his session data being copied from the previous request, from a remote availability zone, and then the session data being stored for the current request, and then his session data might get clobbered or some data might be overwritten. I mean our software can deal with that, but we would rather avoid it rather than deal with it.
In normal circumstances, traffic gets evenly split between all three availability zones. Then it hits load balancing platform in that availability zone and then hits servers. This is like normal circumstances.
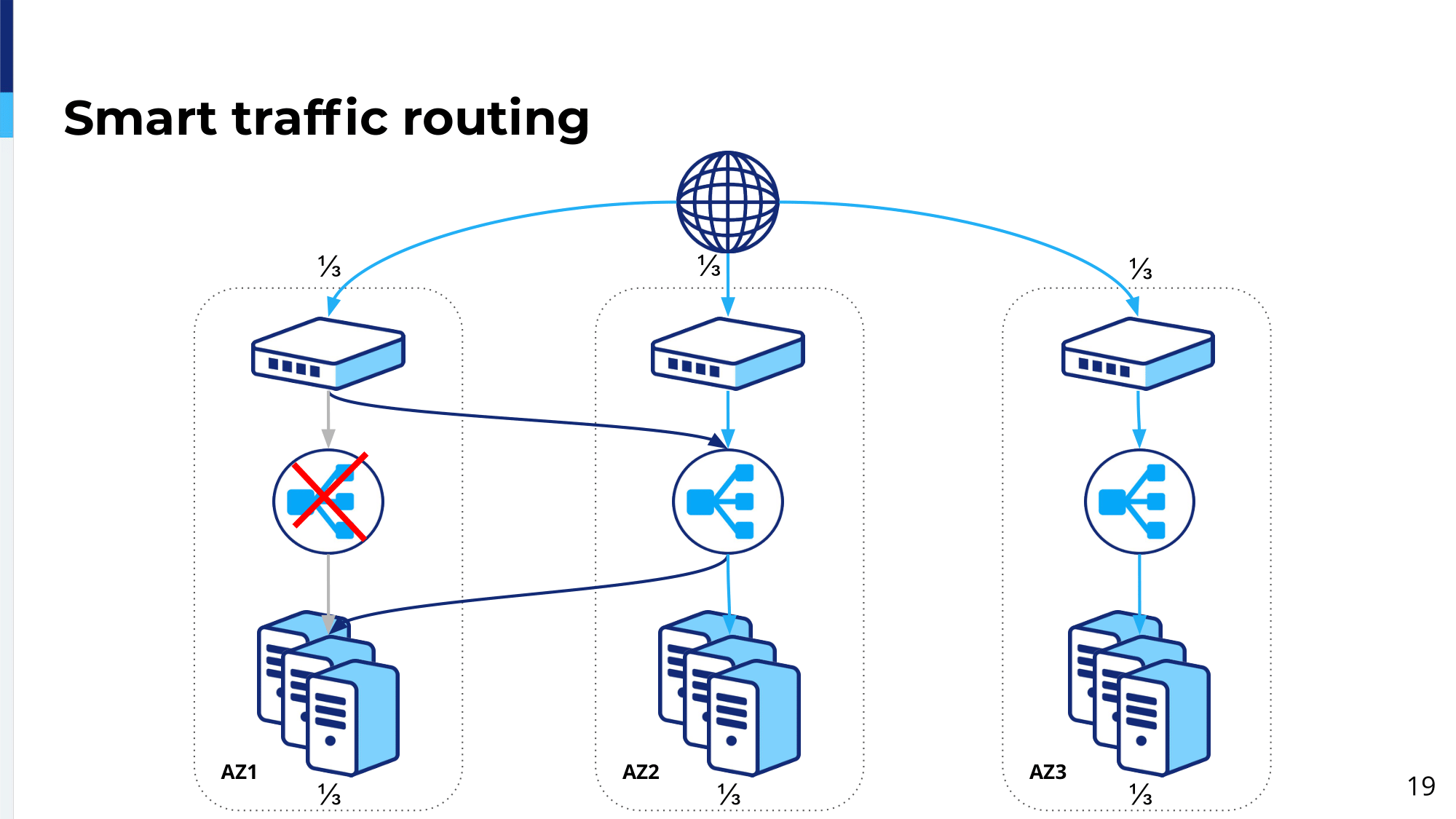
In case of load balancing platform failure in Availability Zone 1, thanks to Anycast traffic from that availability zone will hit the load balancing platform in Availability Zone 2.
Then load balancing platform in Availability Zone 2 will see: This is traffic meant for Availability Zone 1 and servers in Availability Zone 1 are up. In this case, it will forward traffic back to Availability Zone 1. In this case, the even traffic distribution requirement is met. Obviously, we have extra latency for the traffic going through Availability Zone 1, but everyone is happy I guess.
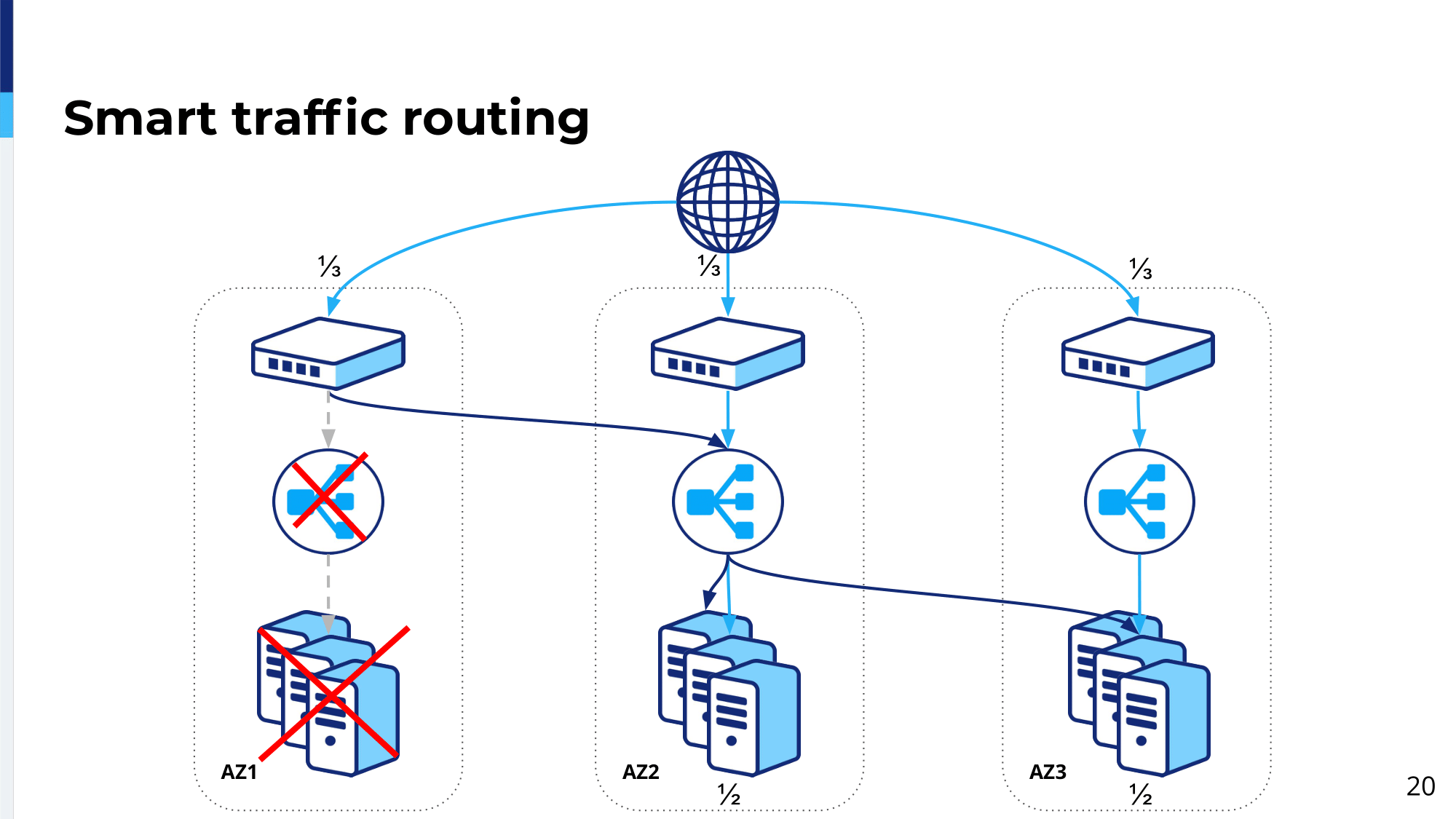
In case of servers being down, similarly to the previous diagram, traffic again will flow to the load balancing platform in Availability Zone 2, but then load balancing platform in Availability Zone 2 will see that servers Availability Zone 1 are down and then it will split this traffic evenly between all remaining data centers. The traffic which goes directly to availability zones 2 and 3 remains as is. We only now are basically splitting traffic between availability zone 2 and 3, and as well we try to keep clients sticky to specific availability zones.
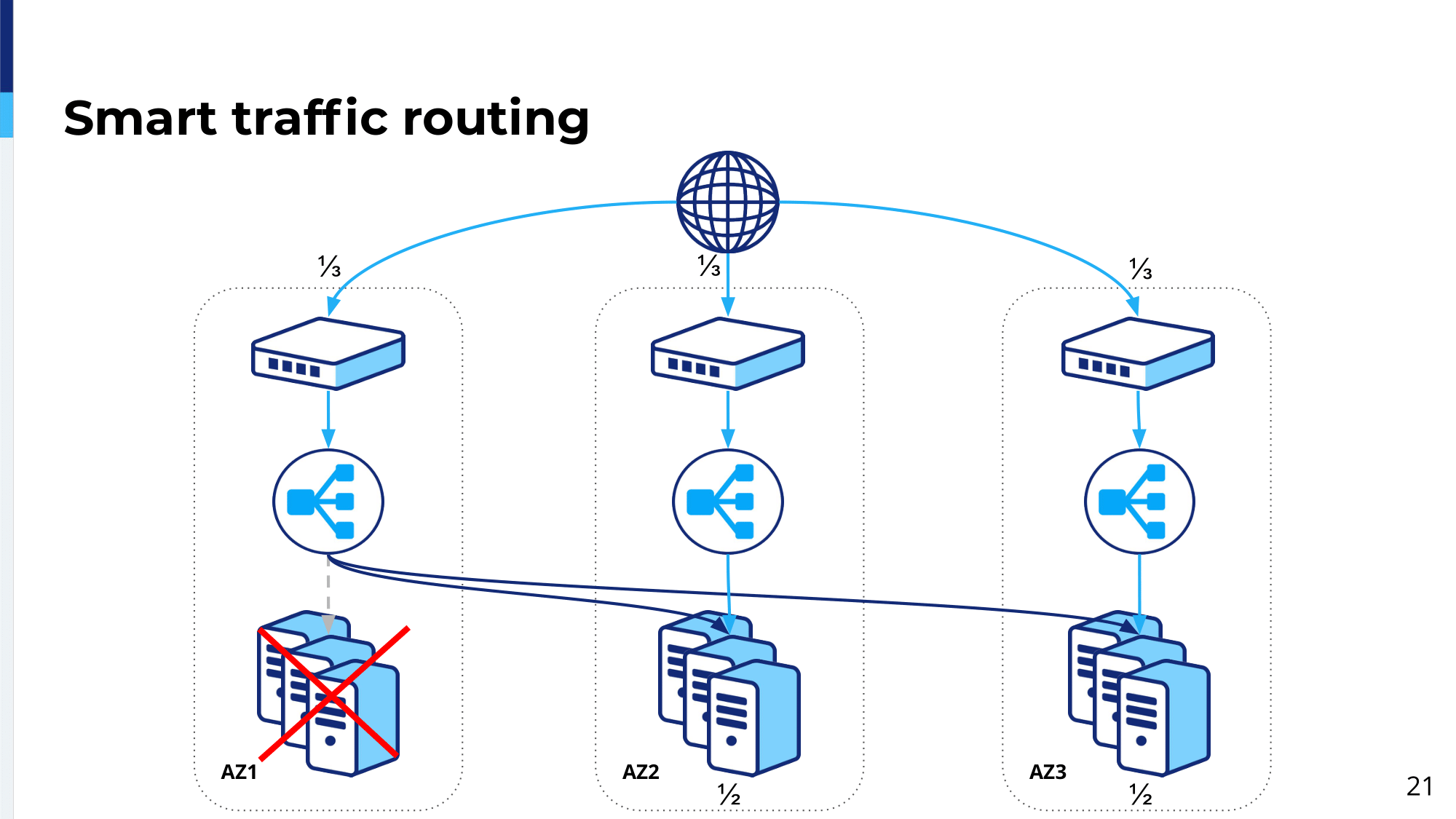
These are the failure scenarios and a more common scenario is this, which is similar to the previous one, where, actually, load balancing platform is up but the servers are down. This could be due to an outage being in Availability Zone 1 or servers being…or a bad rollout there or somebody making…doing a failover when he basically marks all these servers are down. In this case, the load balancing platform in Availability Zone 1 will distribute this traffic among the remaining availability zones.
Present and Future Plans
One of the biggest features, which we developed on top of HAProxy, which was actually developed as context-aware business logic, is smart traffic routing.
What are our current and future plans? Currently, we are in the process of evaluating QuickAssist technology to do SSL acceleration. We want HAProxy to do SSL offloading in hardware. We already have a proof of concept and we are, yeah, we are basically needing to run some tests and get some numbers to actually see how much benefit we could get from the hardware acceleration.
Our platform is HTTP/2 ready, but we ran into some problems and we first need to sort it out before we enable it globally. Obviously, we’re looking forward for HTTP/3, which is an upcoming new protocol; and, as well, one of the features we’re asking HAProxy for is TCP Fast Open on the backend side because TCP on the frontend was available for quite a while, but this is something we would love to try it because we have some setups when actually the latency between the HAProxy and the backend server is relatively high and this would allow us to significantly reduce connect time for all consecutive requests.
And as well we want to provide path-based routing in the Balancer user interface for role owners so role owners can actually define the routing rules for their service, how they want for a specific path where they want traffic to go to. This would allow them to basically specify their own through the user interface without much knowledge of, like, Balancer API voodoo. Through a simple way to define: for this path go here, for this path go there, etc.
In our load balancing platform we use the following open-source software.
I have to mention that the bottom three, so anything below Bird Internet Routing Daemon, was exclusively created for our load balancing platform. You have to keep in mind that some of these can be like partially obsolete or might be obsolete soon. This is due to the fact that when we created our load balancing platform we were dealing with HAProxy 1.5, which was a while ago and some of these functionalities…actually, you know, HAProxy moving forward and basically listens to its customers and implementing some features which people are using.