
In this presentation, Joe Williams describes the architecture of the GitHub Load Balancer (GLB). GitHub built a resilient custom solution on top of HAProxy to intelligently route requests coming from a variety of different clients including Git, SSH and MySQL. The GLB is split into two major components: the GLB Director and GLB proxies. The latter is built upon HAProxy, which provides many benefits including load balancing, advanced health checking, and observability. Live configuration changes happen through a tight integration with Consul. Deployments use a GitHub flow, and include an extensive CI process as well as canary deployments all managed through ChatOps over Slack.

Transcript
Awesome! So, I’m Joe. I work at GitHub and today I’m going to talk about GLB. We started building GLB back in about 2015 and it went into production in 2016. It was built by myself and another engineer at GitHub, Theo Julienne. We built GLB to be a replacement for a fleet of unscalable, it happened to be, HAProxy hosts that the configurations were monolithic, untestable and just completely confusing and kind of terrible. That infrastructure was built long before I joined GitHub but I was there to replace it.
At that point in time, we had a number of design tenets that we wanted to follow when building GLB to kind of mitigate a lot of the issues that we had with the previous system. Some of those were: We wanted something to run it on commodity hardware. You saw in the previous talk about with the F5. We didn’t didn’t want to go down that F5 route.
We wanted something that scaled horizontally and something that supported high availability and avoided breaking TCP sessions anytime we could. We wanted something that supported connection draining, basically being able to pull hosts in and out of production easily, again without breaking TCP connections. We wanted something that was per service. We have a lot of different services at GitHub. github.com is one big service, but we have lots of internal services that we wanted to kind of isolate into their own HAProxy instances.
We wanted something that we could iterate on just like code anywhere else in GitHub and would live in a Git repository. We wanted something that was also testable at every layer so we can ensure that each component was working properly. We also have been expanding into multiple data centers across the globe and wanted to build something that was designed for multiple PoPs and data centers. And then lastly we wanted something that was resilient to DoS attacks because that’s very common for GitHub, unfortunately.

To kind of start things off I’m gonna dig into the request path at GitHub and talking about a few of the open-source tools that we use to manage that; Then, I’m going to dig into the main two components of GLB, which are our DPDK-based director and our proxy, which is based on HAProxy.
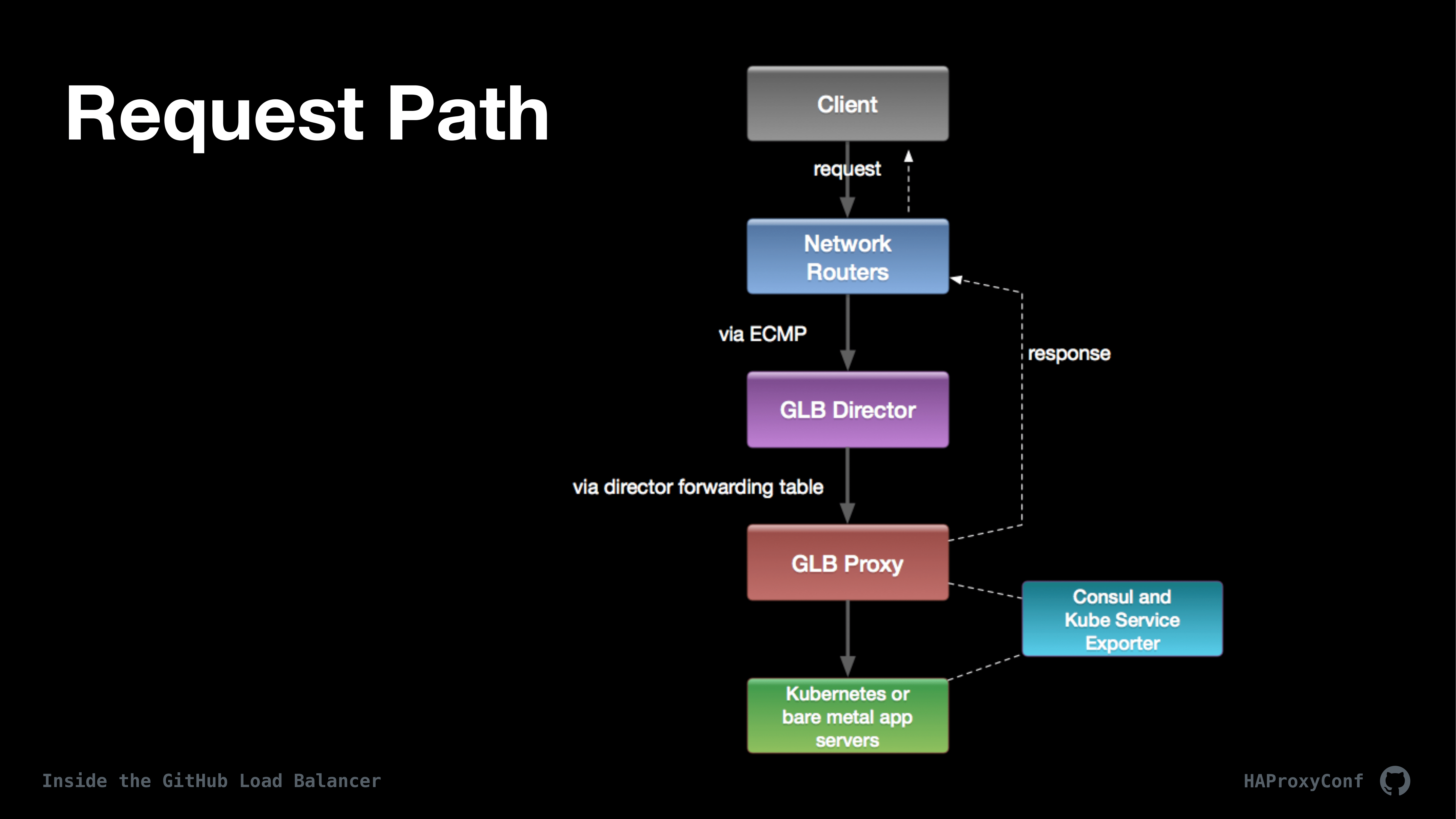
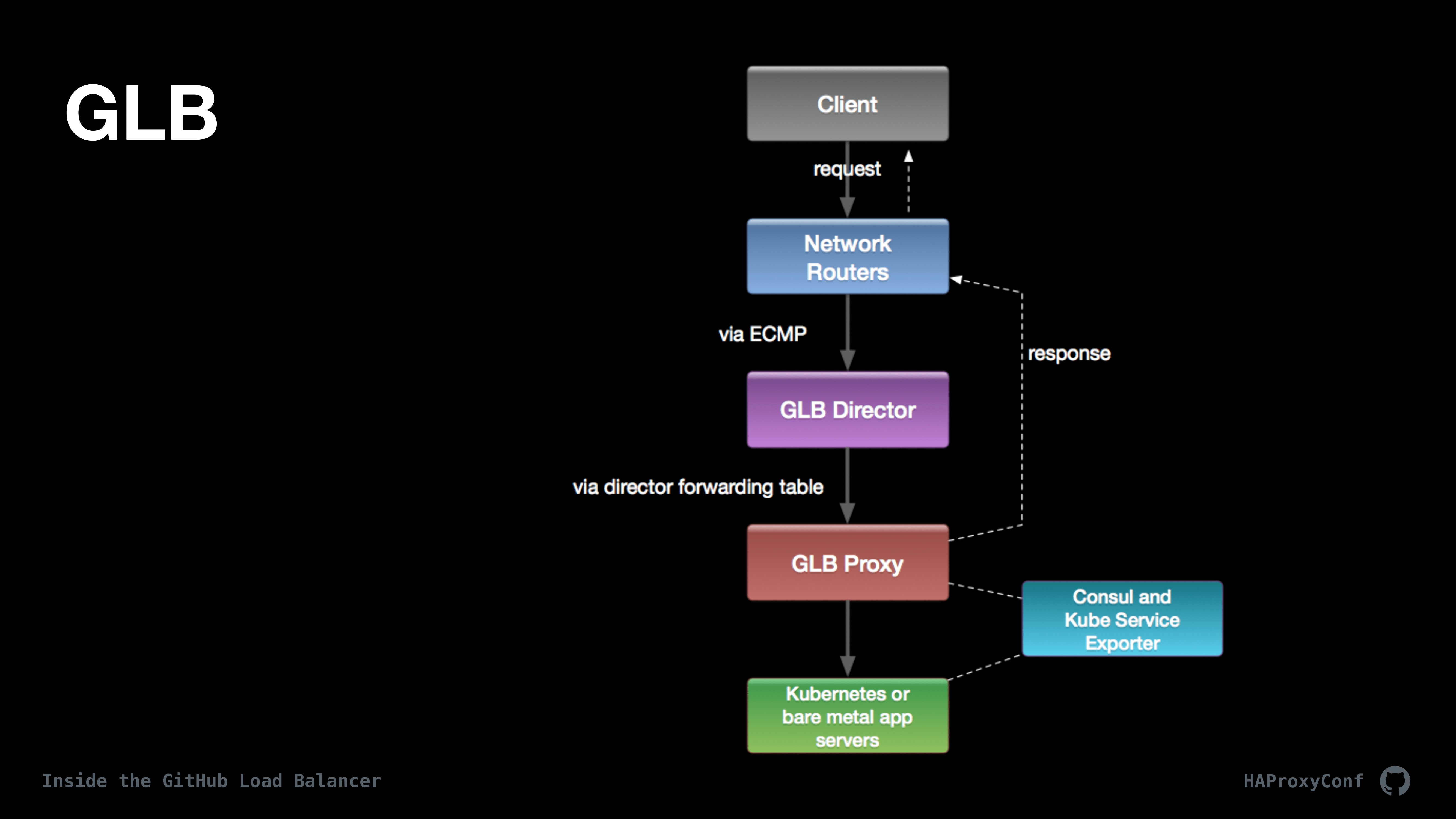
This is kind of a high-level overview of a request path at GitHub. Since we use GLB for both internal and external requests, this flow is for any request into or out of GitHub, basically, and for all services including things like MySQL. After a quick tour of the request flow we’ll get into the two primary components, which is the GLB Director and the GLB Proxy. If you haven’t fully absorbed this diagram we’re going to get into all the details in a bit and I’ll bring it up again.

We’re going to start at the client. We have a bunch of different clients and protocols at GitHub. If you’ve looked in your Git repository config you see it’s github.com. So, that means I have to figure out what clients are HTTP based, which ones are Git based, which ones are SSH, and all those sorts of things. If I could go back in time and talk to the founders of GitHub and say put all the Git traffic on git.github.com, I would have done that; but I have to figure that all out on port 443 or, you know, whatever. So, we have to do lots of crazy things in our HAProxy configurations to figure all that out.
We have clients such as Git and SSH and MySQL and we have kind of internal and external versions of GLB that route all of our traffic. We also…one peculiarity with Git is Git doesn’t support things like redirects or retries. If you’ve ever Control+C’ed during a Git pull, you know that it starts all over again from the beginning; and so, pretty much one of the most important things about GLB is we want to avoid any sort of connection resets or anything like that to keep from killing Git pulls and Git pushes.
One thing we can’t support is something like TCP Anycast. We designed specifically around building things on top of GeoDNS and using DNS as our traffic management instead of Anycast. We manage DNS across multiple providers and authorities and we do all this using our open source project OctoDNS. This is a project that I worked on with a different engineer at GitHub named Ross McFarland.

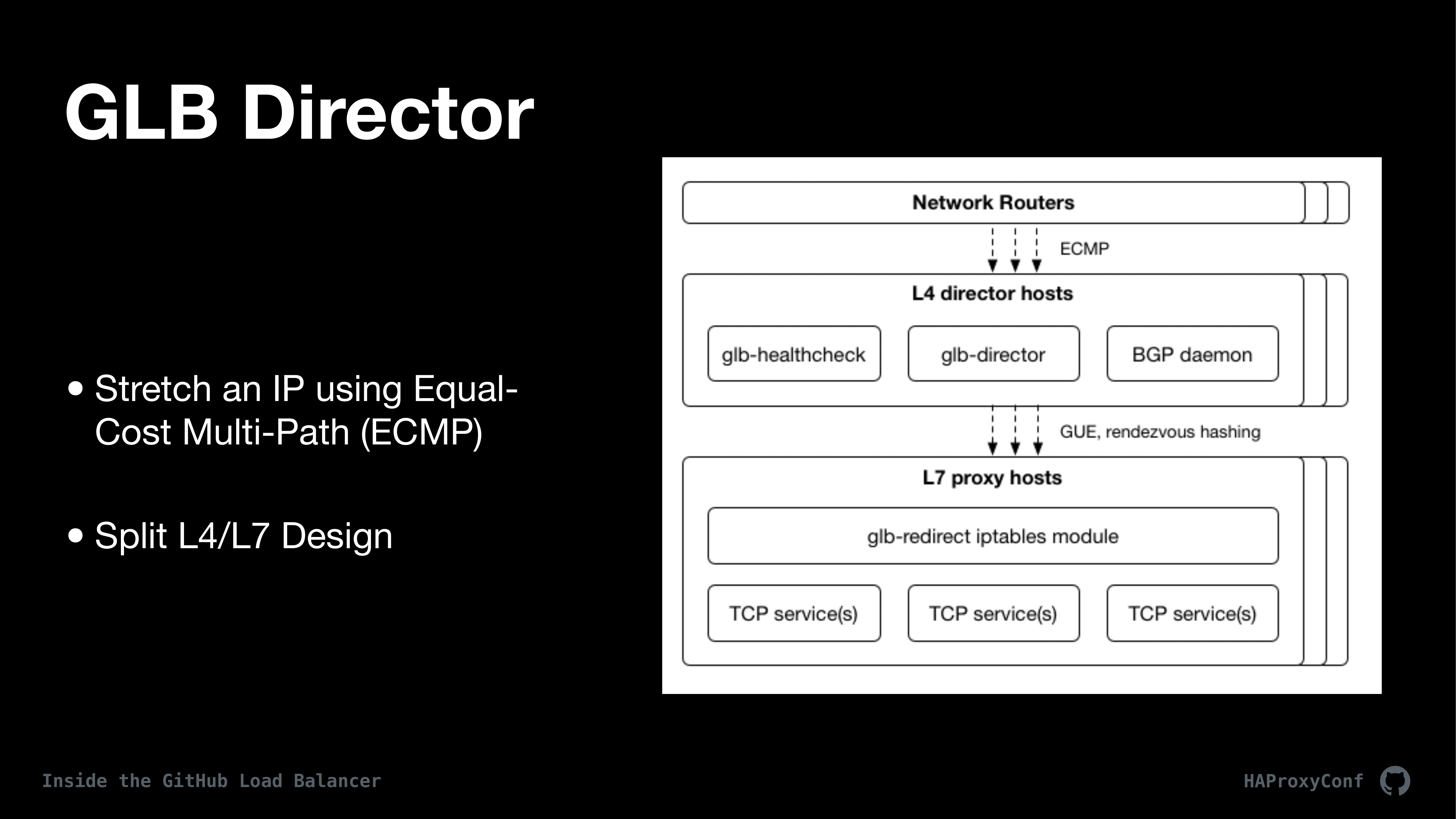
On the edge of our network, kind of similar to the previous talk, we use ECMP and clients make requests and ECMP kind of shards those clients up to our tier of GLB directors. GLB Director is a DPDK-based L4 proxy. It’s completely transparent to the client and to the L7 proxies, using direct proxy return, which uses generic UDP encapsulation.

From the director, the requests get forwarded on to HAProxy, which is all managed mostly using Consul and Consul-Template and using something called Kube Service Exporter, which is our kind of go-between gluing Kubernetes and HAProxy. We don’t use any ingress controllers at all. We talk directly to Nodeports on kube nodes and Kube Service Exporter facilitates that whole thing and again this is all open source.
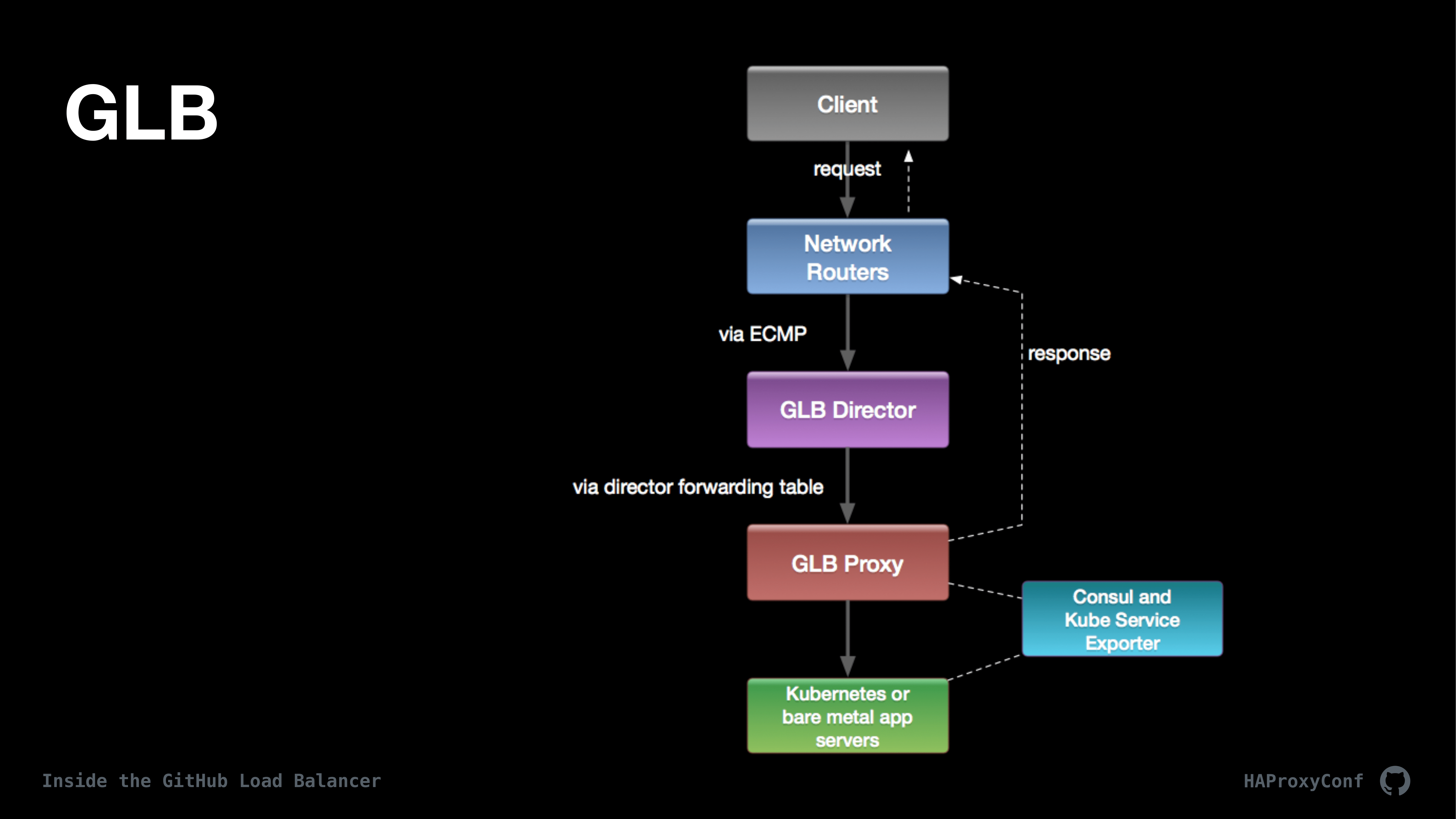
So now we’re going to dig into GLB itself and we’re going to focus on, first, on the director and then everything about the proxy.
So to start off, we load balance a single IP across numerous servers using Equal-Cost Multi-Path and, exactly like the previous talk mentioned, it basically hashes a client for a specific IP across multiple machines. So, you can kind of…we call it “stretching an IP” across a lot of machines.
Earlier we kind of split the design of GLB into an L4 proxy / L7 proxy. One of the nice features about this is that, in general, the L4 proxies don’t change all that often, but the L7 ones do either on an hourly or daily basis; and so we can kind of mitigate some of the risk of updating those configurations.
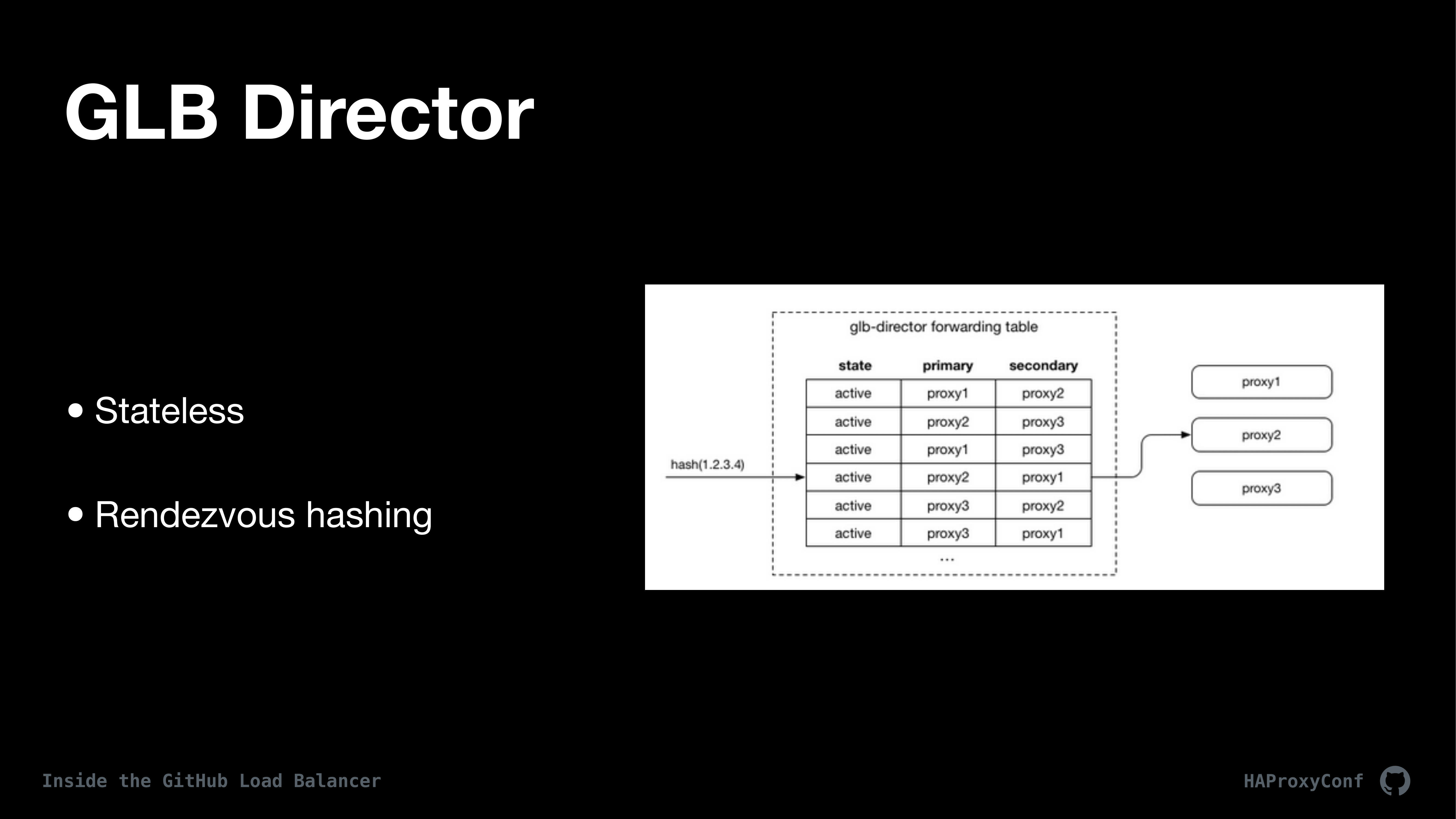
We’ve taken a lot of care in the director to remove as much state as possible. GLB director doesn’t have any sort of state sharing like you might have seen with like IPVS. We don’t do any sort of TCP connection multicast sharing across nodes or anything like that. What we do do is we basically build a forwarding table that’s identical on every single host and it’s kind of similar to like ECMP, where we hash clients onto that forwarding table and then route their requests to specific proxies in the backend.
Each client has their source IP and source port hashed using zip hash and then that hash is then used to assign them to an L4 proxy based on something called a rendezvous hash. That rendezvous hash has a nice property of being able to, basically, when changes are made to the forwarding table only 1/n connections are reset. They’re assigned to that specific host. And so, again, in pursuit of breaking as few TCP connections as we can, we only are breaking the connections of the clients that are connected to the host that is failing. Then, the other way those changes happen is that we have a health check daemon on each of the director hosts. They are constantly checking the proxy hosts and making changes and updating that forwarding table.
.png)
The hash table is also a means of coordinating maintenance for the proxy hosts. So we have a state machine inside the director that we forward or that we process each proxy host through and it’s kind of an example of it here on the slide. This allows us to basically pull proxy hosts in and out of production and be able to drain hosts and then fill them back up without breaking those connections. The only downside to this design is that we have to keep that state table in sync across all the directors, which is only really a problem when we’re in a situation where we’re updating the state table for, like, maintenance or something like that and a proxy host fails because then we have some weird state where traffic is getting routed in a funny way and that kind of thing. Luckily, those things are kind of rare because it doesn’t fail a whole lot.
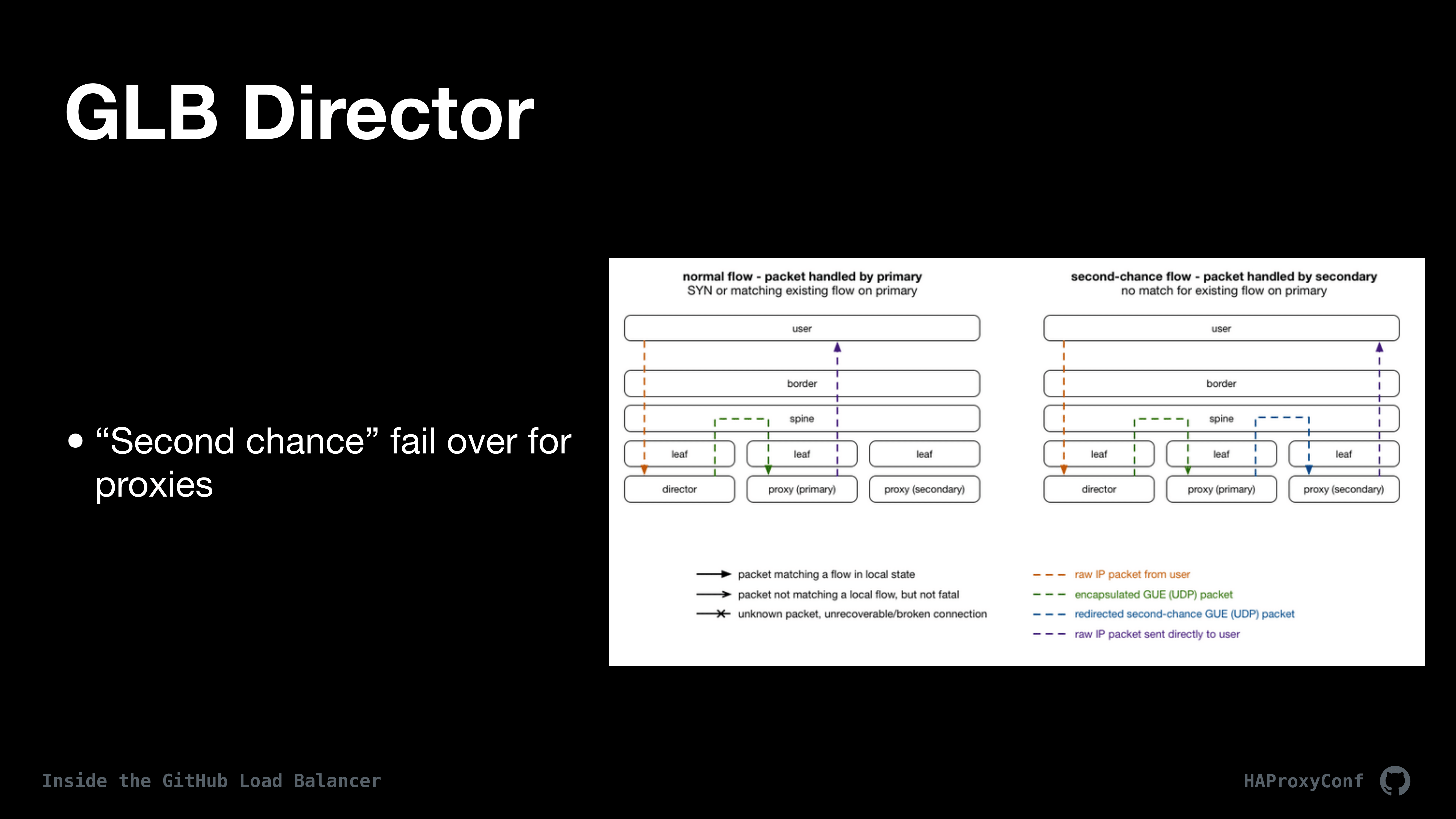
To help mitigate connection resets when we do have some sort of failure, we do something we call “second chance failover” and I think this is one of the neat, novel things
about GLB Director: Is to allow a recently failed host to complete the TCP flow, we have an IP tables module called glb-redirect, that is on the proxy hosts that inspects extra metadata we send in each packet to the proxy hosts, redirecting those packets from the host that’s alive to the host that had recently failed. So that, in the case that the failed host can process a request, it will go ahead and do so. Basically, the way this works is that if the primary doesn’t understand the packet because it’s not a SYN packet or because the packet corresponds to an already established flow, glb-redirect takes that packet and forwards it to the now “failed host” that was in the forwarding table. This metadata is injected by GLB director, which we’ll get into next.

To kind of supply that metadata we use Generic UDP Encapsulation. We decided early on in the design phase of GLB that we wanted direct server or direct proxy return. This has a number of effects, but a few important ones I want to get into. One, it simplifies the design of the director because we’re only dealing with one direction of packet flow. It also makes the director transparent both to the client and to the L7 proxies. So, we don’t have to mess with X-Forwarded-For and that kind of thing. We can also add extra metadata to each of the packets to the proxy tier, which we use to implement the second-chance flow.
We use a relatively new kernel feature called Generic UDP Encapsulation to do this and you can kind of see the example of kind of what the packet looks like there. We add the metadata to that GLB private data area. Before we used Generic UDP Encapsulation, we used something that was in the kernel called Foo-over-UDP, and I think both of these things came out of Google. Basically, what this results in is we’re wrapping every TCP session destined for the L7 proxies in a special UDP packet and then decapsulating on the proxy side as if HAProxy is seeing it directly from the client. So, that’s pretty much most of the Director and I’m going to get into the proxy side now.
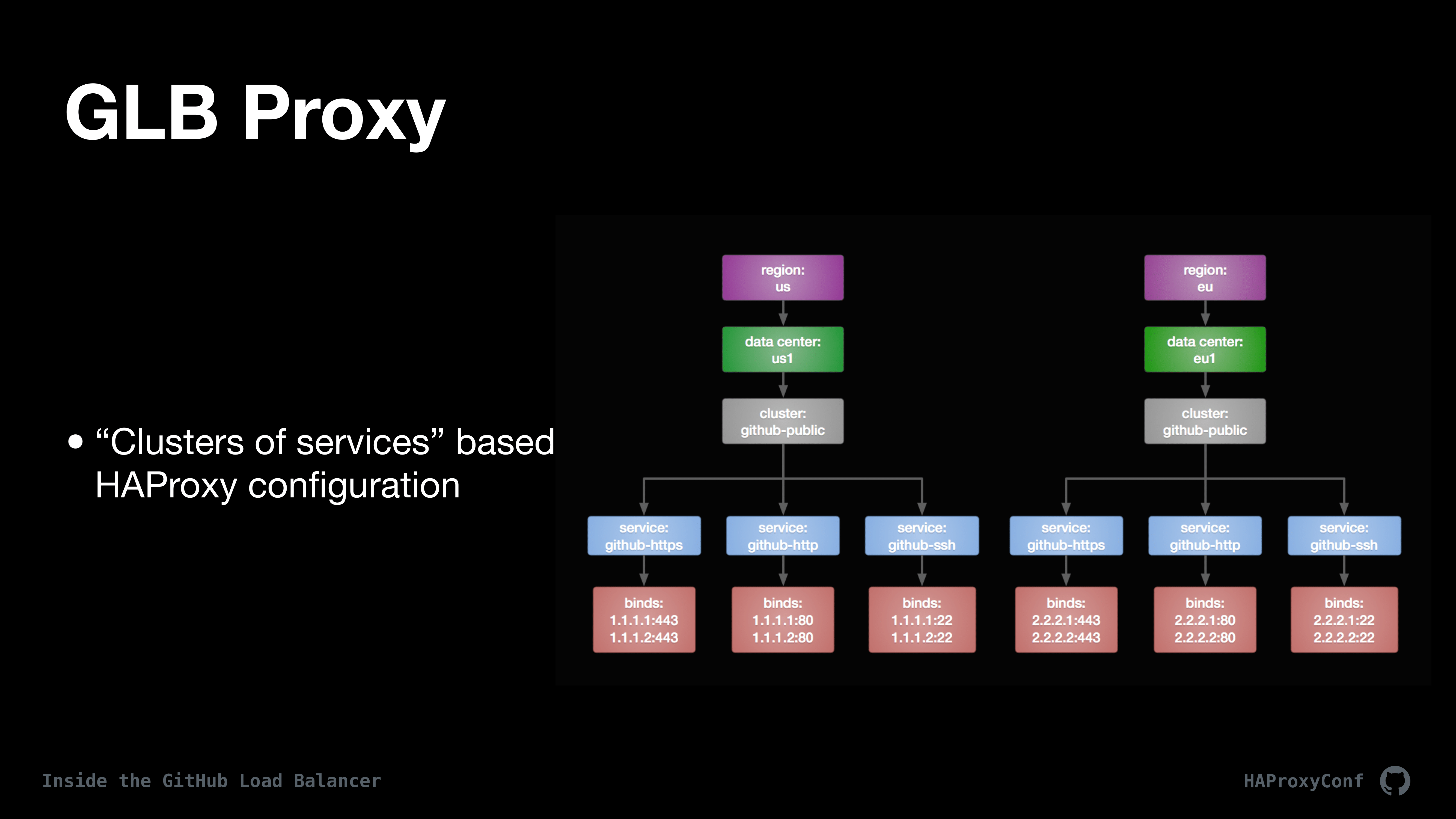
We effectively built out our proxy, or GLB in general, but more specifically our proxy tier in basically clusters of services. This kind of tree diagram gives you a high level of what our configurations end up looking like.
What this kind of results in is we usually split up our HA configurations on their job or service, but we have many configs that happen to be multi-tenant. The service, there’s lots of definitions for the word “service”, and unfortunately, but the way we define service in GLB is that a service is a single HAProxy configuration file, which may be listening on any number of ports or IPs or anything like that. Some of them are protocol specific like I was mentioning earlier. We have Git configs; We have SSH configs; We have HTTP, SMTP and MySQL.
And then a “cluster” in our parlance is basically a collection of these HAProxy services or configurations that are assigned to a specific region, data center, and then we give them a name. In this case, you can kinda see in the tree diagram, you know, we have a region and a data center in a cluster and that cluster is made up of a bunch of services.

What this kind of results in in the real world is we end up building all of our HAProxy configurations in CI. These are pre-built configuration file bundle artifacts. Everything that gets deployed ends up being a configuration that’s prebuilt ahead of time before it ever sees the server.
We used to use Puppet to deploy these configurations, but we decided to do kind of bundled config artifacts. These configuration bundles are deployed separately from HAProxy itself, which is actually managed by Puppet. As you can see in the screenshot of GitHub, we have 48 configuration bundles for GLB itself, which is almost a matrix build in Jenkins, if you’ve seen one of those, and which basically represents…the 48 builds here represent every data center, cluster, and site combination of configuration that we have.

Next up, like during that CI job, we run lots of tests. Literally, my first six months at GitHub was writing something like, I would say, 500 integration tests for that previous generation of load balancer at GitHub. Because we had zero understanding of how it worked and nor had an understanding of how that configuration file was generated and so, in order to move to a new system we had to have some way of writing tests and then ensuring the new configuration would continue to work. In this case, during a CI job, we have a test suite that configures a complete HAProxy GLB stack with real IPs, live backends, in our test environment. Then we use hundreds of specific integration tests that use curl, Git, OpenSSL and any other client that we can think of to run tests against all of those HAProxy instances and invalidate requests that are getting terminated and routed properly.
With this kind of development flow we can effectively do test-driven development, but with HAProxy configs, which I think is pretty neat. In the screenshot you can kind of see one of the test runs and one of the tests itself; and these tests are completely 100% in bash and have worked great for five years.

From CI we now want to try to deploy our configuration. Once CI’s passed, we can deploy it to one or more hosts in our HAProxy…in GLB fleet. Deployments are made of specific Git branches. We use the GitHub Flow, using PRs and everything, just like open-source projects. We usually start with a ”no-op” deploy, which allows us to preview the changes that will be made and shows us the difference between, you know, the current configuration and the new configuration. If the result looks correct, we then move on to a canary deploy. The canary deploy is usually to a single node and then we can watch customer traffic to that node and ensure that things look correct. We then can deploy to an entire cluster and merge the change into master; and that’s all done via Slack and this is an example of Ross doing that.

Once the configuration is out on a proxy host, basically live updates start to happen. And that is all orchestrated with Consul-Template and Consul and Kube Service Exporter. In the case of Kubernetes, we use our own open-source project, Kube Service Exporter, to manage services and Consul. Basically, Kube Exporter is a service that runs inside Kubernetes and exports kube service data. Kube service is different than the GLB service and so it talks to the Kubernetes APIs, pulls back the Kubernetes service information metadata and basically dumps that into Consul. That’s the top piece of JSON there.
We then take that data from Consul and, using Consul-Template, build out HAProxy configurations based on that data. That configuration is what you kind of see on the bottom, which is like an ACL and a use_backend and the backend itself. Like I mentioned, we don’t use Kubernetes ingress controllers whatsoever. We talk directly to the Nodeports on each of the kube nodes. We found that during our initial deployments of Kubernetes that, at least for us, the Kubernetes ingress controllers were kind of an indirection that we really didn’t need because we had such a robust load balancing infrastructure already and had already solved problems like DNS.
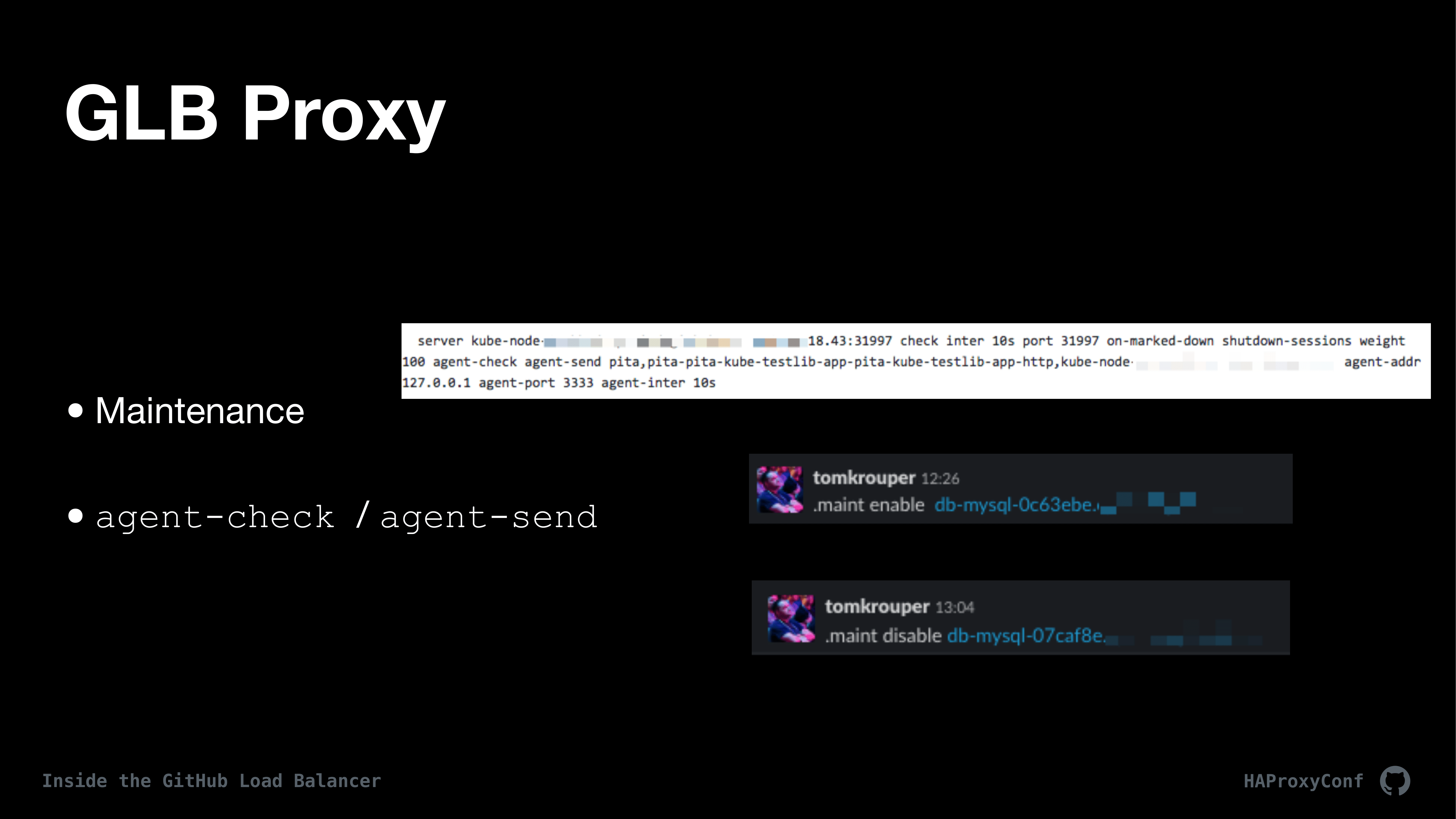
So, once we have a configuration out, we may want to do maintenance. Here’s an example of a server backend line and to do maintenance, what we use is a little service on every single GLB proxy host called Agent Checker. Agent Checker basically knows how to talk to, basically knows how to deal with agent-check and agent-send in HAProxy. Agent Checker stores metadata about the backend and its current status in a local configuration file and is then managed by Consul and Consul-Template. So, we can make changes across the entire fleet. This is how we pull servers in and out of maintenance using ChatOps, like you can kind of see in the screenshot there.
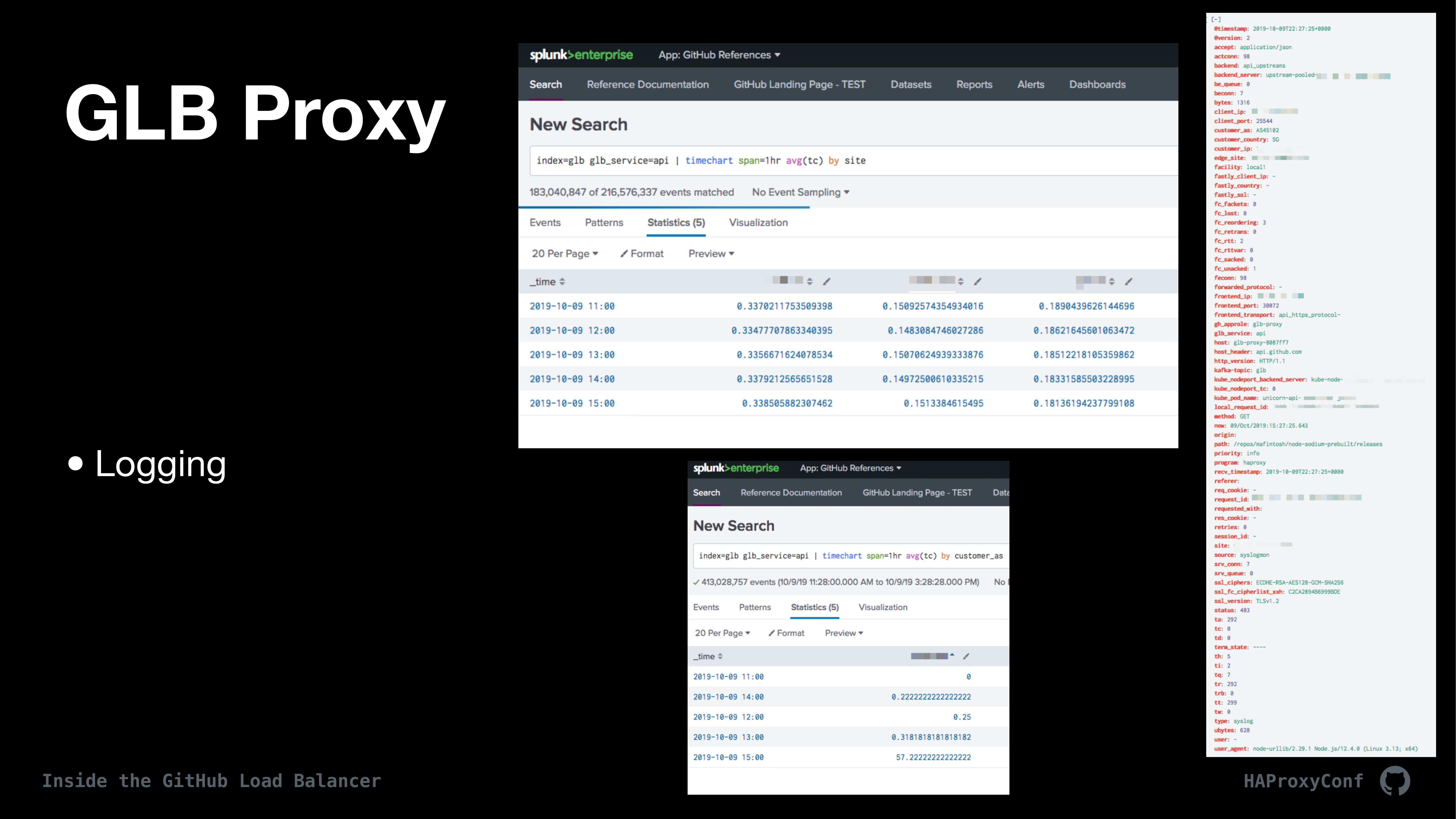
Now that customer traffic is flowing, we want to be able to try to monitor it, obviously. From here, we log just about everything imaginable and dump it all into Splunk so we can kind of slice and dice to data. We also do things like using HAProxy maps to map IP addresses to both countries and Autonomous System Numbers so we can track performance and do reporting.
We also set a unique request ID to every single request and then ensure that services behind GLB include that header all down the flow so we can trace requests through the entire stack. Then, I have a couple of screenshots of Splunk here. I think the top one looks like it’s the client connect time by country and the bottom one is client connect time by autonomous system, for instance. Then, I had to include our server line from Splunk because it’s really big. Similarly we track lots of metrics from both the Director and from HAProxy.
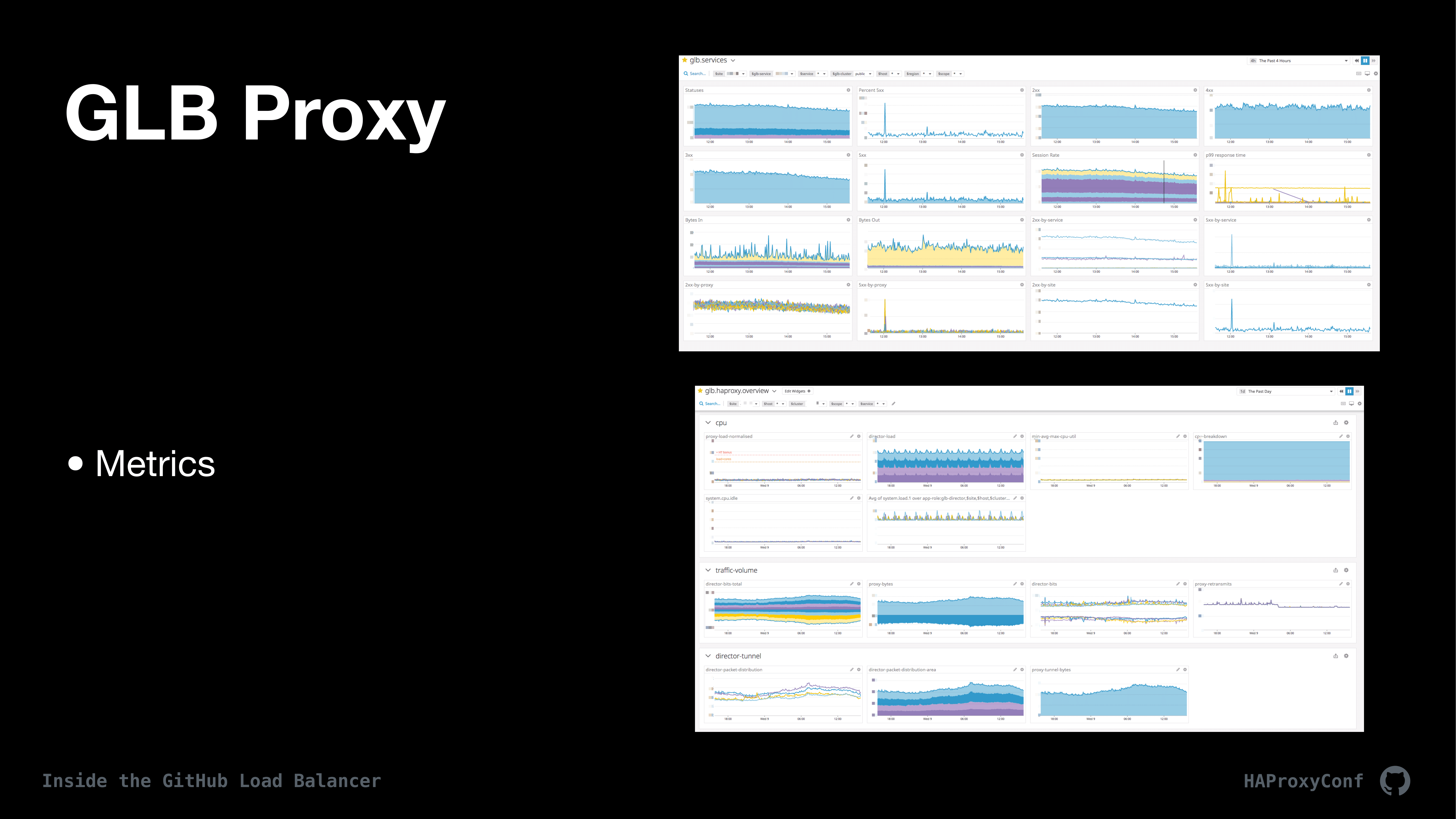
We dump all of these into DataDog currently. We can slice and dice all these by, I think we have like a custom DataDog plugin that adds a bunch of tags for all of the metadata that we want to slice and dice the data from; and so in this case we can slice and deal with looking at GLB clusters by data center, cluster, service host, and just about anything. Various teams at GitHub use these dashboards to monitor the health and performance of GLB and their services behind it, as well as alert on any sorts of issues.
So that’s pretty much it for GLB. As I mentioned, it’s been in production since 2016 and pretty much deals with every single request to every single service at GitHub, both internal and external. Thanks for coming and do you have any questions?