
In this presentation, Andrew Rodland describes the unique challenges of scaling Vimeo’s video hosting platform. Vimeo splits video files into chunks and caches them on separate servers. They use HAProxy’s consistent-hash load balancing to distribute requests to those servers evenly, which allows them to scale horizontally. Andrew developed a new option in HAProxy that fine-tunes consistent-hash load balancing, called hash-balance-factor, that allows a request to consider the current load on the server in addition to whether it has cached the needed video chunk. This consistent hashing feature is essential to successfully delivering video at scale.

Transcript
Thank you very much. I’m Andrew Rodland and this is a little bit about some of the different things that we’re doing with HAProxy at Vimeo, where I am a Principal Engineer on the Video Platform team working with making things reliable and scalable and production-ready and delivering video quickly to people all around the world.

So what is Vimeo? If you’re not familiar, it is a company founded in 2004. We are based out of New York City, but we are all around the world at this point and our thing is video creation and hosting for professionals. So, if you are a website and you want to have video on your site and you don’t want to deal with the details of hosting it yourself and creating a player and all of that, we will give you a fantastic solution. We also have Vimeo Live, which is a live-streaming product, and OTT, which is for people who want to, basically, create a channel. If you want to have your yoga channel and you want to sell subscriptions or sell on demand and be on the web and in apps and all kinds of things, then that’s the kind of thing that we deal with.
It’s a pretty big amount of traffic because, well, video is big. We do 4K, we do 8K, so there’s a lot of bandwidth involved in that. We run on the cloud, primarily Google Cloud Platform. We got into that in 2015 and we shut down our last day datacenter in 2018. So, we’re pretty much entirely on the cloud at this point.

So where in our stack do we use HAProxy? Really, all over the place. There’s the obvious thing, which is put it between your website and the Internet, our API and the Internet. There is Skyfire which is our on-the-fly video packager. Nice, and I’ll speak a little bit more about that. There’s our player backend where the video player gets information about video metadata. Some of our internal systems use MessagePack RPC, which is like gRPC, but older and not as cool. We put it in front of our database replica pools to control access to those. Beanstalk queues, seriously, it’s all over the place.
But the first one I want to talk about is Skyfire, which is our video packager; and something cool that HAProxy allowed us to do with that with an algorithm called bounded load consistent hashing.

A little bit of background on what this thing is and why do you actually need it. So it’s an on-the-fly packager for adaptive streaming, which is when you have a client that is playing video and it’s going to change the video quality dynamically based on the user’s available bandwidth, the resolution that they’re viewing in, maybe they full screened the player, they shrink it down to a window, etc. You want to be able to change qualities or renditions on the fly at pretty much any point.
But Vimeo predates that by quite a few years, so we have a big library of stuff that is stored as progressive MP4, which is basically what you would give to flash player back in the day, what you would give to a regular video tag. It’s just a video file that plays straight through. If you have adaptive streaming, then what you want to do is use a standard like DASH or HLS that breaks the file up into chunks, and at any boundary between chunks the player can switch from a chunk of one quality to a chunk of another quality. So the video data is the same, but it’s in a different kind of container.
If we had really, really massive resources, we could take our existing library of video files and we could reprocess them into DASH and HLS and just serve them as static files; but we don’t have that kind of resources. So, we actually make that conversion on the fly and it needs to be fast because it is in the loop of video playback. The player is requesting the next segment of video and it needs it now because it only has so much video in the buffer and nobody likes when that little spinner goes buffering buffering buffering.

So, our traffic looks like about 300 gigabits at the edge. That’s what users are actually requesting from us. CDN absorbs a good portion of that, but at the origin for this particular kind of adaptive traffic we are pushing out 35 gigabits, about 7000 segment requests per second. Converting those container formats is pretty easy computation-wise. It’s not transcoding. All of the audio and video stream bytes are the same, but some of the metadata that’s around them, time codes and bit formats, and things like that have to get modified in certain ways.
But in order to do that we need to know when the user requests chunk number 1, 2, 3 of a video, which bytes of the original file are we actually going to ship out and wrap in this particular packaging and send to the user? So before we can do that we have to look at the global headers of the video file and find out for every little bit of audio and every little bit of video in the file, where does it start and end? Both in terms of time and in terms of bytes within the file. If we know that, then we can build a map and we can say, “Okay, I want this chunk number 1, 2, 3. It’s going to be from this many segments in until that many segments in.” And so, we can know exactly which byte ranges in the file correspond to that. We can load them up, we can do the container transformation and we can send them to the user and we can do that in under ten milliseconds if we have the index.
But actually computing that index is pretty expensive. We need to request a big chunk of the video file from storage, which comes with a latency penalty; and then we need to spend a lot of CPU computing based on that, where, actually, all of these segments are. If we did that on every segment request it would be too slow; It would be too expensive. So the obvious thing to do here, again we don’t want a massive batch processing job on millions of videos to do this in advance. So, we do it on demand, but we need to cache it. That way, the first time it’s going to take a moment. The video is going to start up playback, but all of these later requests are going to have the information already ready to go.

So, when we were building this thing out and first putting it in front of a small segment of our users, what we figured we could do was: Well, we have HAProxy and HAProxy is great and what we can do is just have this cache in memory on the server that is doing the indexing and that is sending out this data; and HAProxy has consistent hash load balancing based on, for instance, a URL segment, the part of it that says which video clip we’re trying to send to the user. Consistent hashing means relatively stable assignment to servers because we’re in the cloud. Servers come up, servers go down. We autoscale. They can go away at any moment because it’s the cloud, who knows?
With naive modulo hashing, say you have nine servers and you scale up to 10, then that means that nine parts out of 10 of your content will be hashed to a different server. But with consistent hashing, if you have nine servers and you go up to 10, then only one out of nine moves. So you can scale up, scale down, lose a server without massive interruption and that means that the cache will be mostly effective.
The problem is hot spotting, and hot spotting is based on two things. First is that there’s randomness in the consistent hashing algorithm that naturally causes some servers to get a bigger portion of the hash space than others. There’s ways to control that, but it’s always going to happen. The other is not all content is equally popular. It’s, in fact, it’s very far from that. Some content is thousands of times as popular as other content that we’re serving. So, if you say that this piece of content belongs to this specific server, then one server might be in for a whole lot load and that caused overload on the servers. It caused a lot of delays, a lot of latency shipping out the content and buffering problems in video playback.
So, we weren’t able to stick with that route. What we did instead was in addition to the in-memory cache that’s on the machines, add a shared cache, use Memcached; Switch the load balancing from consistent hash-based to least-connection based, which is another thing that HAProxy can do; Send the request to the server that is doing the least work right now. All servers will be pretty evenly loaded and you don’t have to worry about hot spotting.
The problem is that the bandwidth to that shared cache becomes pretty massive because we’re no longer trying to send a request to a server that’s going to have that index in memory. So more likely than not, it’s going to have to get it from the shared cache. The more traffic we get, the more we scale up, the more servers we have, the less likely it is that the request is going to find its way to a server that happens to have the right data in cache. So, the bigger we get, the more traffic goes to that shared cache, which is potentially a huge bottleneck to scalability.
In 2016 already we were pushing multiple gigabits out of this shared cache in order to feed the packaging process and we could see that that was probably not going to be sustainable forever.

What we really wanted would be a way to do consistent hashing, but to have more control over it.
If you can, then you should be able to send a request to a server based on the hash that you know is very likely to have the thing that you want in cache. But if that would make the server too busy compared to the average, then it should go somewhere else. And if you have to go somewhere else, then that should be chosen consistently too so that your second choice…that way, if you do have a very popular video then your second choice will have it in cache, maybe even your third choice will have it in cache because they’re all sharing that load.
This is good for a very specific kind of workload, which is not something that everybody has, but it’s something that we very definitely did have. Where we have a cluster of servers, any server in that cluster is able to serve a request, but some of them can do it with less resource usage than others.

It turns out that I was sitting at work, not writing code, going through my Twitter feed one day, and somebody sent me—or not even sent me—somebody posted to Twitter a link to this paper which was called Consistent Hashing with Bounded Loads. I read the abstract and it spoke directly to me. It said, “Andrew, this is how to do the thing that you were asking to do.” And it came my way about less than a year after we had this thing in production, so before the shared cache had had a chance to grow into a real problem. It’s a very, very simple algorithm that you can describe in a page, that you do the consistent hashing thing, but you compute a load number for each server and you say if I was to add one more request to this server, would its load become greater than so much times the average? Say 125% of the average. If it would, then just go to the next entry in the consistent hash ring, which will be a different server. Check the load on that one. If it’s okay, send it there. If not, keep going.
I was like, “This is so simple even I can do it.” And we’re using HAProxy. So, I opened up the source, I took a look, I figured, “Yeah, I think I can manage this.” So, in 2016, towards the end of 2016, I sent a patch to [the] HAProxy mailing list. With a little bit of back and forth, it was accepted. It got in just in time for HAProxy 1.7. So, it is available for everybody to use. If you’re using hash-type consistent in a configuration, all you have to do is add this config option hash-balance-factor, which is a number of relatively how much difference in load can you tolerate between different servers, and if there would be more than that much difference in load, then it will go to a different server.
We put that into production at Vimeo before it was even merged into master and it did the job beautifully. It allowed most of the indexes to be served from the local cache, not to have to go to the shared cache. But there was no hot spotting problem. There was no problem with the servers getting overloaded. Everything was just humming along nicely.
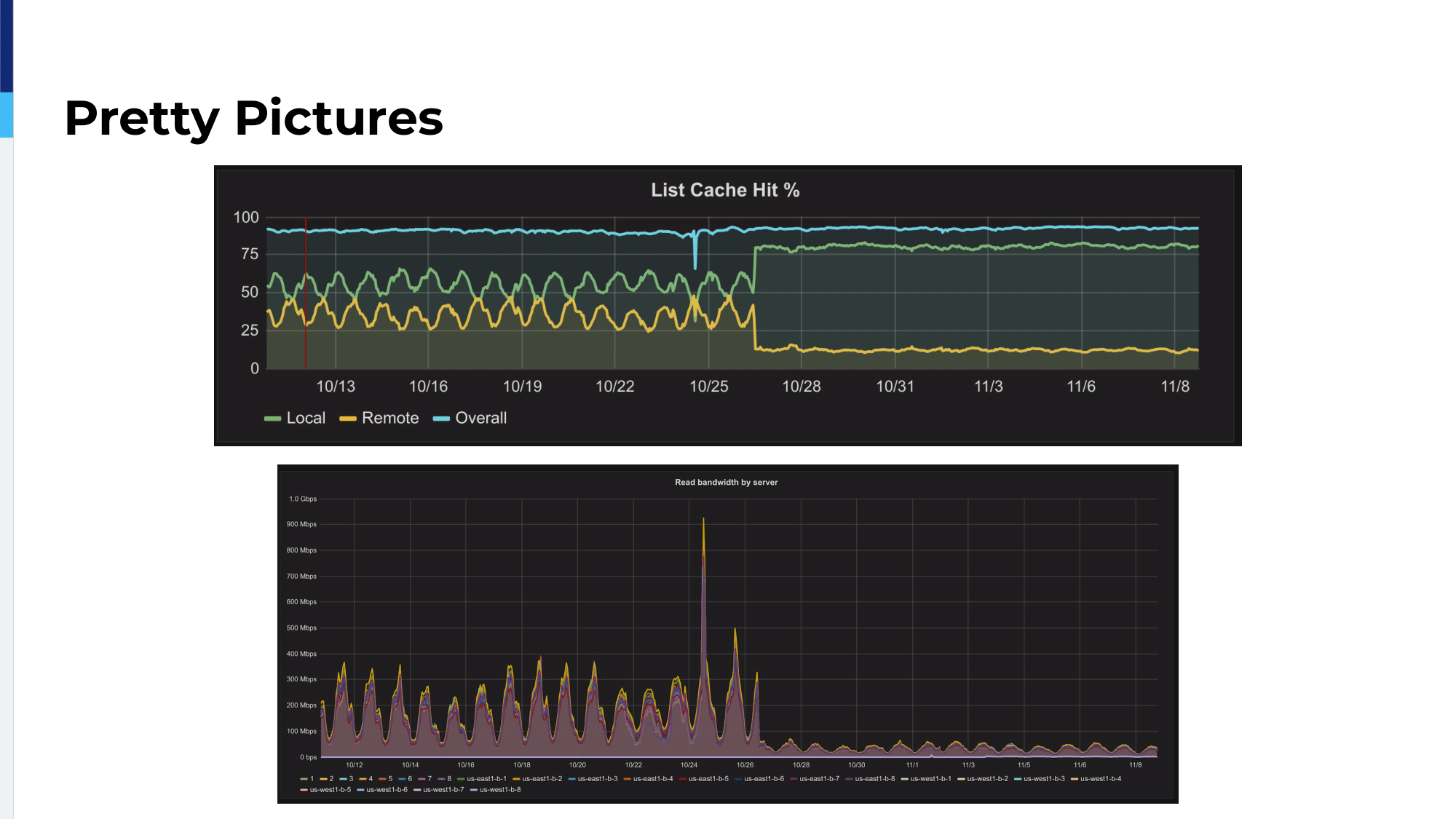
This is some graphs from back in 2016. The upper one is actually our metrics of what percentage of these indexes are getting fetched from the local in-memory cache and what percentage of them are being fetched from Memcached. And you can see that in the previous…previous to this change it was going up and down in a daily pattern, which was our load pattern because, as I said, the more load we get at certain times of day, the more servers we scale up to, the more servers we have, the less likely it is that you’re going to find the thing that you want on that server with purely random assignment. So, the cache becomes less efficient during periods of higher load.
And then, 1026 and 1027 there, we deploy just a change to the HAProxy config and not only is the local cache percentage substantially better, it’s also very consistent. You can see that it’s no longer moving with our traffic. It’s no longer moving with our number of servers. Since then, and you can also see in the lower graph, this is the actual bandwidth usage of the shared Memcached, which we push down by a factor of like six, something like that. I can’t read it off of there right now.
Since then, our traffic has grown substantially, I believe by about a factor of three. The Memcached bandwidth has gone up by about 10%. So, that was the scalability win that we wanted. We’re no longer worried that Memcached bandwidth is going to saturate and bring down the whole thing.
Something that I forgot to put in my slides, but in the next version, HAProxy got multithreading and that was an additional win on top of this because we were running multi-processing: eight processes on eight CPU servers. With multi-processing, the load tally for each server was separate for each process. So, if you think about it, a request comes in and it’s trying to do this assignment based on the relative load of each server. But when the request comes in it’s only able to see 1/8 of the picture. So, we switched from multi-processing to multithreading, went from eight processes to eight threads.
Now, each one is able to see the entire picture and it caused, actually, slightly better assignment of requests to servers. It made it more likely to go to the first choice because you have less variance that way. We were very happy with this and we were really happy to get such a win and to be able to contribute it to a piece of open-source software that we rely on.

Actually, a few weeks ago my boss sent me another paper by the title of Random Jump Consistent Hashing, which came up because it specifically cites this previous paper; and they said we have an improvement on this algorithm that gives massive improvements in the equality of load distribution. I spent some time reading it. Okay. You only get massive improvements if you start with the wrong configuration to begin with. If your consistent hashing uses virtual bins, which HAProxy implementation does, then you’re not going to get as large gains as they claim. If your hash-balance-factor in your HAProxy config is something reasonable like 1, 2, 5 is what we use, which corresponds to epsilon equals one quarter in the scientific notation. Then, the gains are not going to be nearly as large as the worst case that they want to highlight in their paper.
But even with those, I estimated that we can get about a 20% decrease in the load variance compared to the algorithm that’s currently in HAProxy, which, again, just means more even balancing without sacrificing that cache locality, which means a potential for more performance, more requests per server. It hasn’t happened yet because the way that it selects the next server to go to if the first server is unavailable would require a little bit of refactoring in how HAProxy actually does hashing and I haven’t had time to dig into that because all kinds of things. So, it’s not there yet, but it’s something that I’m excited to look into and squeeze out a little bit more performance and upstream that as well.

The next topic that I have for you is a related one to this, which is we’re in Google Cloud. We’re using Google Cloud Platform. We’re using Google load balancers, but we’re also using HAProxy and why do we want to have both of those? Doesn’t that sound kind of redundant? But we like HAProxy. We use HAProxy features that you can’t just get from Google load balancer or ELB, like, for instance, bounded-load consistent hashing. But, we don’t want, for instance if we front everything with HAProxy, we don’t want our services to go down if a VM running HAProxy goes down because, again, cloud VMs. They can go down at any time.
Sometimes we have more traffic than you can handle through a single HAProxy fronting VM. So, what we do is we put HAProxy behind Google TCP-mode or SSL-mode load balancer. So, we don’t allow it to run in the intelligent HTTP mode. We just say either proxy TCP connections directly to an instance group or SSL terminate us, TLS terminate us, and then proxy the connection to an instance group.

So, we still get any HAProxy features that we want to use. HAProxy is running in a mode where there is health checking, auto-healing, autoscaling. We can roll out a whole new HAProxy image without having to do, you know, hot upgrades or anything like that. We can just bake a new image, do a rolling restart to the cloud and have that happen. We can put it behind a Google global load balancer and have multiple HAProxy pools and have the load balancer select the one that we like.
We can have Google take the load of TLS termination off of the HAProxy VMs. It’s not as much of a problem as it used to be, but hey, they provide the TLS and a non-TLS service for the same price. So why not free up that CPU to be used for something else. Besides which, then we don’t have to actually get the secrets onto the VMs. We can just put the secret into the managed thing that is on Google. So, if we can do that, why not?

One thing that we have run into in that process is, again, we have these, in many cases, autoscaled, where we actually bring up and down the size of the HAProxy pool based on the amount of load that we have. Google has a feature called connection draining, which is when it decides to scale down, when it schedules an instance to go away, it can in the load balancer stop new connections from coming into that machine. It will wait a configurable amount of time, up to 10 minutes, for all of those connections to terminate. Great! But we’re using a TCP load balancer, which means that it’s not aware of anything inside HTTP. It’s not aware of HTTP Keep-Alive.
Our CDNs want to use Keep-Alive for very good reasons; We want to use Keep-Alive to keep latency down and everything else. We would really like to know if we are being put into that draining interval, this instance is scheduled to go away, and then we could do something in HAProxy, put it into graceful mode so that it could start saying Connection Close to everybody who sends it a request and then we could, you know, actually allow most of those connections to terminate, but we don’t get that notification. The only notification we get is the 60-second warning that says in one minute I’m going to hard terminate your VM whether you like it or not.
At that point, we can send send a signal to HAProxy and it will start sending Connection Closed to everybody and the connections will start to move away, but you can imagine, you know, if you have a user on a slow connection doing a large file download, 60 seconds is not going to be enough time and there’s going to be some interruptions for the places that we are using it. It hasn’t caused a major problem, but it is a bit of a caveat. What we did before this was basically just to have a fixed size pool of HAProxies and give the addresses of all of them to the CDN without involving the load balancer and that is more stable in a way, but when we wanted to get scalable we came up with this solution.

Another thing that we are using in our system is HAProxy logs going into StatsD because we like observability. I will preface this: We also have the logs going to, you know, actual durable log storage where log lines are, like, retain their identity in detail, but for quick and easy viewing we want to just be able to see some graphs.
So, we have a Go service that is baked into our image that is colocated with every instance of HAProxy and it listens on localhost for UDP Syslog lines. We tell every HTTP backend: option httplog, send to this log server and it will parse the log line, extract all of the information, all of the interesting details out of it, and generate a bunch of StatsD timer and counter metrics, latency, amount of requests, amount of requests broken down by the HTTP status, frontend connection counts, backend connection counts so that we can see if we’re getting near any limits, and we can break it down by all kinds of interesting things.
This is just a quick example of what we can get out of that. It’s not super exciting, but it’s real time, it’s real important and we can have monitoring hooked up to this. We can say, if a service gets more than such and such percent of error responses, if we have major load imbalances, if one region starts to misbehave in a bad way, we can see all of that. StatsD, Graphite, it’s a little bit of old tech, but talk to the guys at Booking. It’s also really powerful.

Another topic that we have is I mentioned we’re using MessagePack RPC as backend communication between some of our servers and we would like to be able to health check them. MessagePack RPC is, it’s what it sounds like. MessagePack is a binary encoding, kind of a Protobuf kind of thing, but more free form, more in the spirit of JSON; very, very compact. So, this is actually health checking one of our services. Don’t worry, you don’t need to read the binary. I broke it down for you and this is just to show really how simple of a format this is.
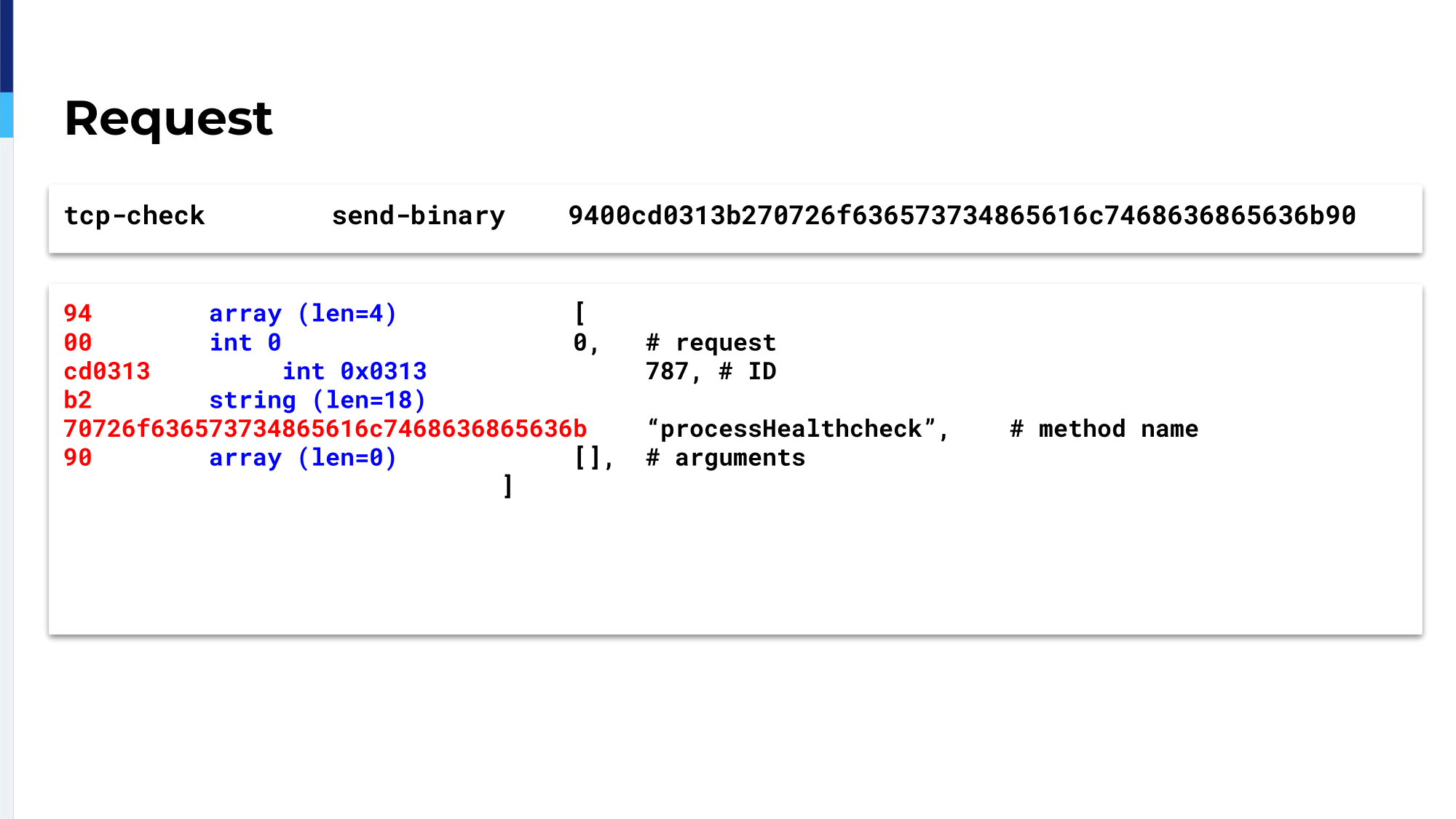
This is the request and it says a request is an array. It’s an array of four elements. If the first element is zero that means it’s a request and not a response. Every request has an ID. This is an arbitrary number, but you get that ID back in the response. The next thing that you get is the name of the method that you want to call. All of our services have a method named processHealthCheck and the next thing is an array of the arguments. We don’t need any arguments for processHealthCheck, so empty array, takes one byte to code. So altogether, this is like 30 bytes.
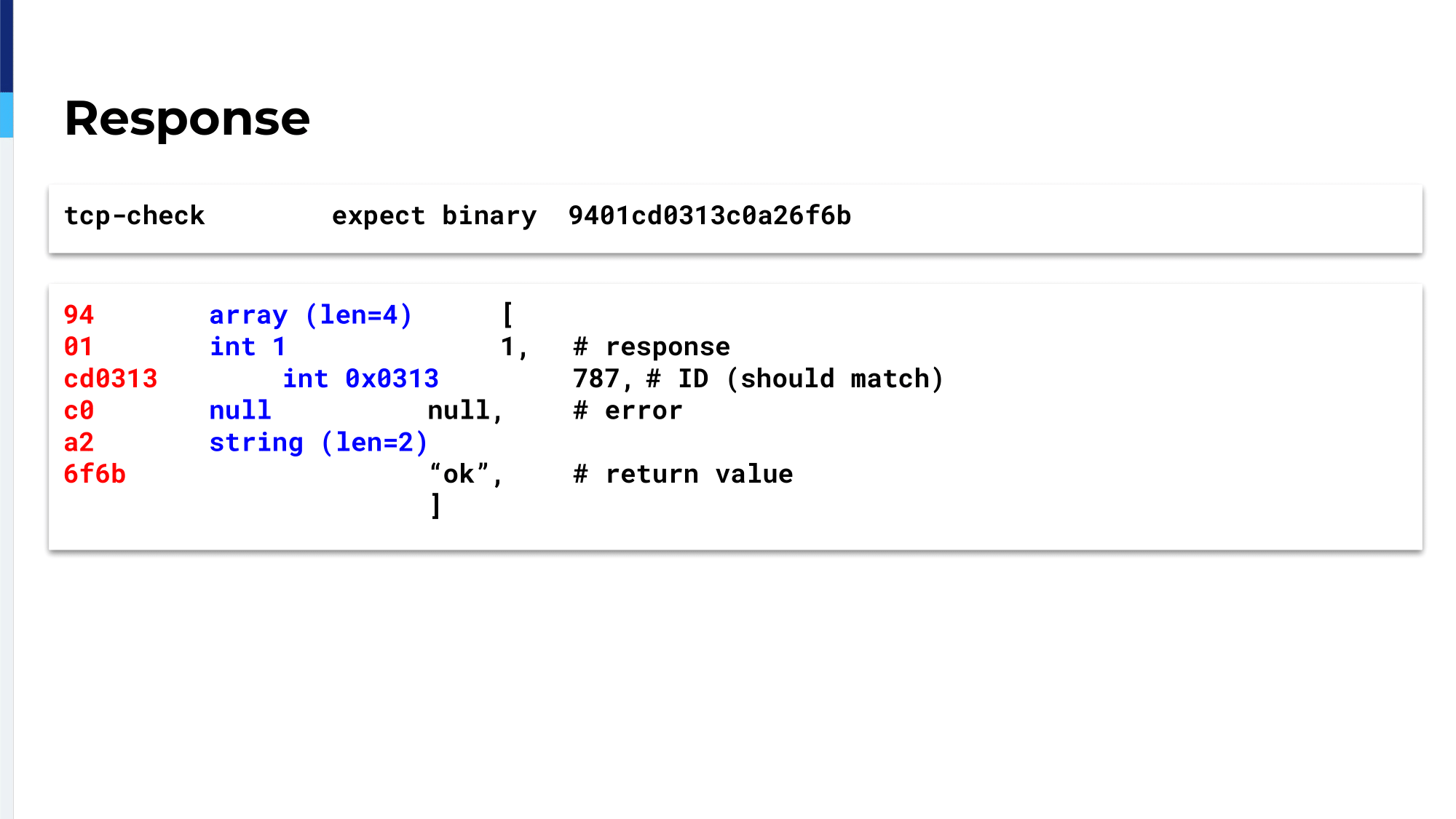
Here’s the expect string. This is what it’s always going to send back. It’s another array of four elements. If the first thing is one, that means it’s a response. The ID should be the same ID that we sent in the request. The error should be nothing. We don’t like errors and we code the method to always return this string “ok”. So, if it says ok, that’s a pretty…it’s a deterministic response. ID is the same as you sent, error is nothing and return value is ok. If we get that, then we say that the service is healthy.

So it’s really nice that HAProxy has a TCP check.

We also use HAProxy in blue/green deployments on some of our services and the cool thing that I want to highlight about that is just that we have HAProxy talking to itself. We have the actual frontend listener, listens on the external port and all it does is it says talk to myself on a Unix socket. One of these is active, one of these is inactive, and we have two more listeners on those Unix sockets that go to the actual servers. They support health checking, they do all of that stuff. They’re also accessible via TCP port for developer troubleshooting and for the script that actually manages the deployments.

So, when we do a deploy we have a script. It’s a Python thing. It talks to HAProxy admin socket, figures out which pool is the active one, which is the inactive one. On the inactive one, we’re going to roll out a new version of the service. We’re going to wait for it to be complete. We’re going to access the service through that TCP port that we have configured in HAProxy to make sure that it actually registers as live. We query what its version is to make sure that the version is actually the one that we expected it to be deploying; and then, assuming that all of that goes well, then we talk to the admin socket again and tell it activate that new pool, deactivate the one that was active before. And that is all of the things.